
Wie man im Jahr 2026 ein KI-Ingenieur wird: Fähigkeiten, Fahrplan und Tools
Drei KI-Engineer-Rollen, die sechs Ziffern verdienen — und welche passt zu Ihrem Hintergrund

Sie lesen dies, weil Sie bereits die Mathematik zu KI-Engineer-Gehältern durchgerechnet haben — 130.000 bis 250.000 USD+ in den USA laut Daten zur Vergütung aus der Schulungsindustrie von Dataquest — und Sie möchten wissen, was es wirklich braucht, um dorthin zu gelangen. Das U.S. Bureau of Labor Statistics prognostiziert 35% Wachstum für Computer- und Informationsforschungswissenschaftler (die Kategorie, die KI-Rollen einschließt) von 2022 bis 2032, weit über dem 4%-Durchschnitt für alle Berufe, laut BLS. Die Gelegenheit ist real. Ebenso real ist die Frage, wie man KI-Engineer wird, wenn die Hälfte des Internets Ihnen einen Bootcamp verkauft.
Hier wird es unangenehm. Eine IEEE-Spectrum-Analyse von Stellenausschreibungen aus 2025 ergab, dass 68% der Ausschreibungen mit dem Label „AI Engineer" tatsächlich fortgeschrittene Softwareentwicklung mit minimaler KI-spezifischer Arbeit beschreiben, laut IEEE Spectrum. Übersetzung: Mehr als die Hälfte der Stellenausschreibungen, auf die Sie sich bewerben, wollen nicht das, was der Titel sagt, den sie wollen. Titelinflation ist das am wenigsten gehütete Geheimnis des Marktes.
Dieses Stück tut nicht so, als würden Sie in 90 Tagen eingestellt. Es vermittelt Ihnen die tatsächliche Abfolge — welche Spezialisierung Sie wählen sollten, welche Grundlagen wichtig sind (und welche Sie überspringen können), wie Sie ein Portfolio erstellen, das ein GitHub-Klick eines Senior Engineers überstehen kann, und wie Sie Fähigkeiten in Angebote umwandeln. Keine Bootcamp-Affiliate-Links. Kein Hype.
Inhaltsverzeichnis
- Drei KI-Engineer-Rollen, die sechs Ziffern verdienen — und welche passt zu Ihrem Hintergrund
- Grundkenntnisse, die Sie wirklich einstellen lassen (und die Theorie, die Sie überspringen können)
- Die 12-Monats-KI-Engineer-Roadmap: Ein vierteljährliche Abfolge
- Portfolio-Projekte, die Recruiter-Callbacks bringen
- Das KI-Engineering-Toolkit: Was tatsächlich in der Produktion verwendet wird vs. Lebenslauf-Polsterung
- Fähigkeiten in Angebote umwandeln: Das Netzwerk- und Interview-Spielbuch
- Häufig gestellte Fragen zum Werden eines KI-Engineers im Jahr 2026
Drei KI-Engineer-Rollen, die sechs Ziffern verdienen — und welche passt zu Ihrem Hintergrund
„KI-Engineer" ist nun ein Sammelbegriff. Einstellungsmanager bei Anthropic, Stripe und der Mayo Clinic suchen nach drei unterschiedlichen Profilen, und die erforderlichen Fähigkeiten divergieren nach Monat drei des Lernens stark. Wählen Sie eine, bevor Sie ein Lehrbuch wählen. Eine späte Wahl bedeutet, verschiedene Framework-Stacks in Monat sieben neu zu erlernen — das ist der häufigste Grund, warum Karrierewechsler ausbrennen.
ML-Engineer. Trainiert Modelle, entwirft Experimente, skaliert Trainings-Pipelines. Umfangreiche Mathematik: Lineare Algebra, Wahrscheinlichkeit, Optimierungstheorie. Dies ist der Weg bei Unternehmen mit proprietären Daten-Assets — Netflix-Empfehlungen, Spotify-Ranking, Stripe-Betrug. Sie werden mehr Zeit für Feature Engineering und Evaluierungsstrenge aufwenden als für den Aufbau benutzerspezifischer Systeme. Gute Übereinstimmung für Hintergründe in CS, Statistik, Physik oder angewandter Mathematik.
LLM/GenAI-Engineer. Erstellt Anwendungen auf Basis von Foundation Models. Schwerpunkt auf Prompt Engineering, Retrieval-Augmented Generation (RAG), Evaluierungs-Harnesses und parametereffizientes Fine-Tuning mit LoRA oder QLoRA. Häufig bei KI-nativen Startups und Enterprise-Teams, die interne Copiloten ausliefern. Die am schnellsten wachsende Spezialisierung bei Einstellungen 2025. Gute Übereinstimmung für Product Engineers und Full-Stack-Software-Engineer — Sie wissen bereits, wie man ausliefert; Sie lernen die Modellierungsschicht.
AI Systems / MLOps-Engineer. Besitzt Bereitstellung, Überwachung und Infrastruktur-Zuverlässigkeit. Schwerpunkt auf Docker, Kubernetes, Model Serving (Triton, BentoML) und Observability-Tools (Weights & Biases, Arize). Häufig in regulierten Branchen — Finanzen, Gesundheitswesen, öffentlicher Sektor — wo Produktionsstabilität wichtiger ist als neuartige Modellierung. Gute Übereinstimmung für Backend-Engineers, DevOps und Site Reliability Engineers, die den Modell-Lebenszyklus zu ihrem bestehenden Toolkit hinzufügen.
| Rolle | Mathematische Tiefe | Primäre Tools | Typische Gehaltsspanne (USA) | Bester Einstiegshintergrund |
|---|---|---|---|---|
| ML-Engineer | Tief | PyTorch, scikit-learn, Spark | $128K–$220K+ | CS, Statistik, Physik |
| LLM/GenAI-Engineer | Moderat | Hugging Face, LangChain, LoRA, Vector DBs | $130K–$250K+ | Softwareentwicklung |
| AI Systems / MLOps | Leicht (System-Ebene) | Docker, K8s, Triton, MLflow, W&B | $135K–$230K+ | Backend, DevOps, SRE |
Gehaltsspannen aus Dataquest-Schulungsindustrie-Vergütungsdaten — überprüfen Sie gegen Levels.fyi für spezifische Angebotsbereiche.
Der Markt belohnt noch keine Generalisten. Er belohnt Spezialisten, die ein funktionierendes System in ihrer Spur innerhalb von neunzig Tagen nach der Einstellung ausliefern können.
Laut Stanfords HAI 2025 AI Index Report haben 56% der Unternehmen nun dedizierte KI-Engineering-Rollen, gegenüber 32% im Jahr 2023. Die LLM/GenAI-Spezialisierung wächst am schnellsten bei Enterprise-Einstellungen, aber die MLOps-Spur hat die höchste Angebots-Konversionsrate, weil das Angebot wirklich begrenzt ist — Backend-Engineers, die MLOps-Tiefe erworben haben, sind seltener als neu ausgebildete LLM-Bastler.
Kreuzen Sie dies mit der IEEE-Feststellung zur Rollen-Inflation ab. Der größte einzelne Hebel, den Sie auf Ihre Jobsuche anwenden können, ist nicht der Titel — es ist der Abgleich Ihrer Spezialisierung mit der tatsächlichen Arbeit, die in einer Stellenausschreibung beschrieben wird. Lesen Sie den Abschnitt Verantwortlichkeiten. Wenn eine „Senior AI Engineer"-Rolle „RESTful APIs entwerfen, PostgreSQL-Abfragen optimieren und mit Stripe-Webhooks integrieren" auflistet, ist das eine Backend-Rolle mit KI-Buzzwörtern. Fahren Sie fort.
Grundkenntnisse, die Sie wirklich einstellen lassen (und die Theorie, die Sie überspringen können)
Die meisten KI-Engineer-Roadmaps stellen sechs Monate Multivariablenrechnung und Maßtheorie an den Anfang. Das brauchen Sie nicht, um eingestellt zu werden. Sie brauchen ein funktionierendes Verständnis von fünf Bereichen — genug, um ein Paper zu lesen, ein Modell zu debuggen und einen Kompromiss in einem Interview zu erklären. Dr. Michael Chen vom CMU Software Engineering Institute analysierte 500 selbstgelehrte KI-Engineer-GitHub-Repos und fand, dass nur 12% richtige Evaluierungs-Frameworks implementierten, laut CMU SEI. Die Lücke, die Angebote tötet, ist selten „mehr Mathematik". Es ist Produktionsdisziplin.

Lineare Algebra und Rechnung — nur das funktionsfähige Subset. Sie brauchen: Matrixoperationen (Multiplikation, Inverse, Transponierung), Eigenwerte und Eigenvektoren auf intuitivem Niveau, Gradienten und die Kettenregel, grundlegende Wahrscheinlichkeitsverteilungen. Sie können überspringen: Echte Analyse, Maßtheorie, formale Beweise. Die kostenlose 3Blue1Brown-Serie „Essence of Linear Algebra" auf YouTube deckt ungefähr 80% des funktionsfähigen Wissens in etwa vier Stunden ab. Wenn Sie die Rückwärtsausbreitung auf Papier für ein zweischichtiges Netzwerk ableiten können, haben Sie genug.
Python — das KI-Ökosystem, nicht nur die Sprache. Über Syntax hinaus: NumPy Array Broadcasting, Pandas groupby, merge und Time-Series-Operationen, PyTorch Tensoren und Autograd, async/await für API-Arbeit und modernes Packaging mit Poetry oder uv. Einstellungsmanager testen List Comprehensions, Decorators und Context Manager in technischen Screenings — nicht algorithmische Rätsel, die Sie in einem FAANG-Interview sehen würden. Werden Sie fließend in idiomatischem Python, bevor Sie ein Modell anfassen.
Statistik und Evaluierungs-Design. Hypothesentests, Konfidenzintervalle, A/B-Test-Design mit Stichprobengrößenberechnung und Mehrfach-Vergleichskorrektur sowie Model-Evaluierungs-Metriken, die über Genauigkeit hinausgehen: Precision/Recall-Tradeoffs, ROC/AUC-Kurven, Kalibrierung, BLEU und ROUGE für Text sowie LLM-spezifische Evaluierung (LLM-als-Richter, Golden Datasets, Retrieval Recall@k). Laut dem NIST-Rahmen für KI-Risikomanagement sollten Produktionssysteme mindestens auf einem kurierten Evaluierungssatz mit dokumentierten Bias- und Leistungsschwellwerten getestet werden. Wenn Ihr Portfolio-Projekt einen Evaluierungsbericht fehlt, liest es sich als unvollständig.
SQL und Data Wrangling — unverzichtbar, auch für LLM-Engineer. Jedes Produktions-KI-System ruft Daten aus einer Datenbank ab. Sie brauchen: Joins (inner, left, Window Functions), CTEs, Query-Optimierung (Indexes, EXPLAIN-Pläne) und mindestens eine Vector-Datenbank — pgvector, Pinecone oder Weaviate — für RAG-Arbeit. Hadoop komplett überspringen. Lernen Sie Spark nur, wenn Ihre Ziel-Stellenausschreibungen explizit davon erwähnen. DuckDB ist das unterbewertete Juwel, das zwei Wochenenden Studium wert ist.
Git, Docker und eine Cloud-Plattform. Branching-Strategien (Trunk-basiert oder GitHub Flow), Schreiben von Dockerfiles, die keine 8GB-Image-Aufblähung erzeugen, und Bereitstellung auf AWS, GCP oder Azure. Sie brauchen Kubernetes nicht für Ihre erste Rolle. Die meisten KI-Engineering-Teams behandeln K8s als Plattform-Team-Territorium, nicht als Verantwortung des Modellierungs-Engineers. K8s auf Ihrem Lebenslauf ohne ein echtes Projekt, das es nutzte, liest sich für erfahrene Interviewer als Lebenslauf-Polsterung.
Das Ziel ist nicht ein CS-Grad-Wert an Theorie. Es ist genug Fließfertigkeit, um auszuliefern. Wenn Sie ein Modell trainieren, es auf einem gehaltenen Satz evaluieren, es hinter einem FastAPI-Endpunkt bereitstellen und Ihre Evaluierungs-Methodologie in einem Interview verteidigen können — haben Sie die Messlatte für die große Mehrheit der Junior-KI-Engineer-Rollen überschritten.
Die 12-Monats-KI-Engineer-Roadmap: Ein vierteljährliche Abfolge
Schulungsanbieter wie Dataquest schlagen vor, dass ein Software-Engineer in 3–5 Monaten übergehen kann — bezeichnen Sie das als Herstellerschätzung, nicht als Brückenkonsens. Die CMU-SEI-Analyse legt nahe, dass dieser Zeitrahmen für produktionsqualitative Arbeit für jemanden, der bei Null anfängt, unrealistisch ist. Der realistische Zeitrahmen: ungefähr 12 Monate Teilzeit (15-20 Stunden pro Woche) für einen Non-CS-Hintergrund, um einstellungsfähige Kompetenz zu erreichen, etwa 6-8 Monate für einen arbeitenden Software-Engineer, der KI-Spezialisierung hinzufügt. Diese Roadmap geht vom längeren Weg aus. Komprimieren Sie auf Ihr Risiko hin.

Quartal 1 (Monate 1–3): Core Python + Math Refresh + First Shipped Notebook
Täglicher Fokus: 60% Python-, Pandas- und NumPy-Praxis, 30% Lineare Algebra über 3Blue1Brown und Khan Academy, 10% Lesen von KI-Engineering-Stellenausschreibungen, um zu internalisieren, was „bereit" in Ihrem Zielmarkt aussieht. Das Lesen von Ausschreibungen ist keine Prokrastination — es ist Marktforschung.
Empfohlene kostenlose Ressourcen: fast.ai Practical Deep Learning Course 1, Kaggles „Intro to Machine Learning"-Spur und der Hugging Face NLP Course. Alle drei sind wirklich kostenlos und von Praktikern gebaut, die ausliefern.
Portfolio-Meilenstein: Einen Kaggle-Wettbewerbs-Eintrag mit einem öffentlich zugänglichen Notebook, das Ihre Feature Engineering-Entscheidungen und Modellwahlrationale dokumentiert. Ausstiegskriterien: Sie können eine CSV laden, ein baseline scikit-learn-Modell trainieren, es auf einem gehaltenen Satz evaluieren und in einem Absatz erklären, warum Sie Ihre Evaluierungs-Metrik über die Alternativen gewählt haben.
Quartal 2 (Monate 4–6): ML-Grundlagen + First End-to-End Projekt
Täglicher Fokus: scikit-learn Tieftauchgang, Model-Evaluierungs-Strenge, Intro zu PyTorch. Themen, die wichtig sind: Regularisierung, Cross-Validation, Hyperparameter-Tuning, warum Ihr Test Set undicht war (es wird), und Kalibrierung. Der am meisten verbreitete Fehlermodus für selbstgelehrte Engineers: Trainings-Set-Leistung, die dem Kontakt mit echten Holdout-Daten nicht standhält.
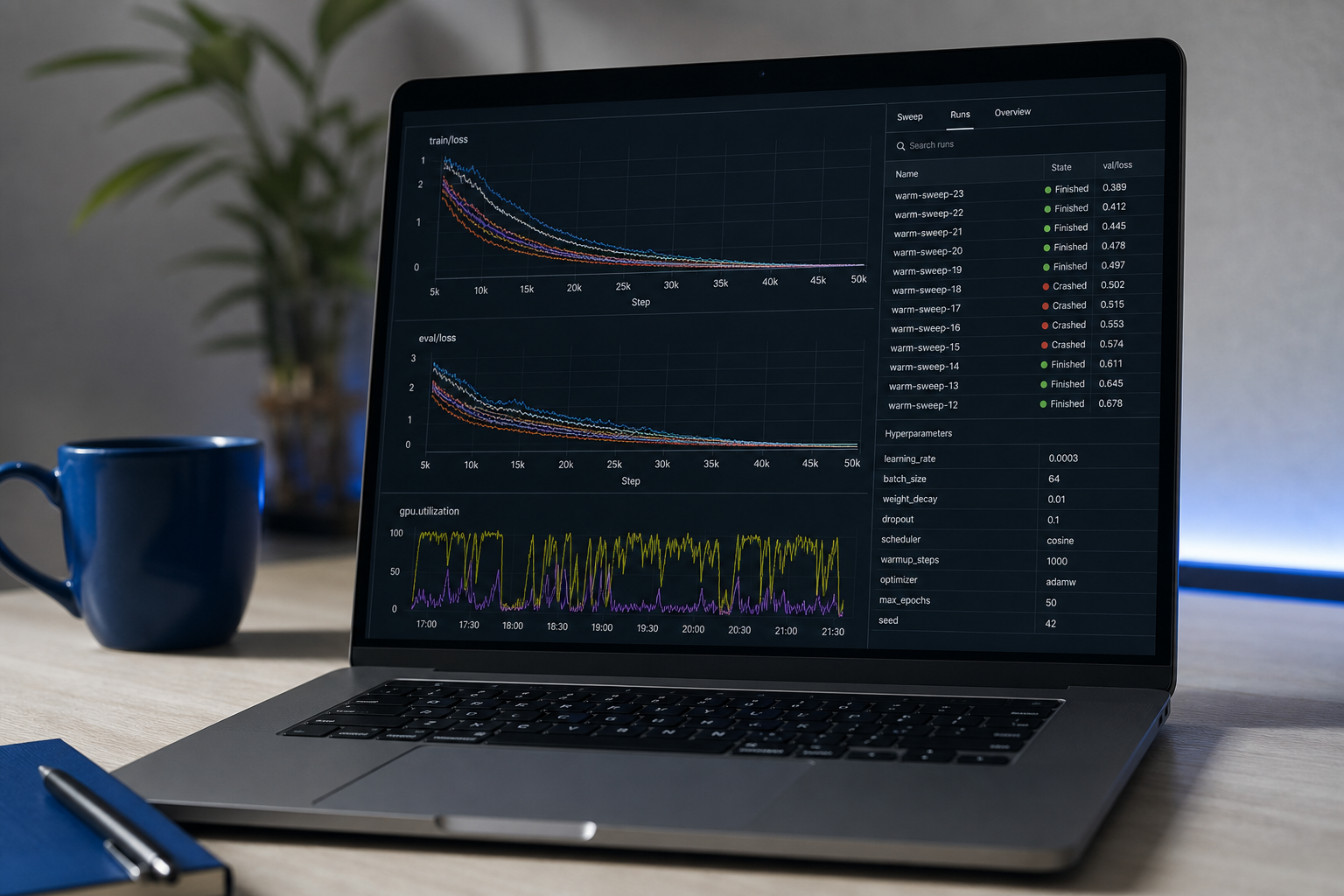
Portfolio-Meilenstein #1: Ein End-to-End-Projekt mit bereinigten Daten, einem trainierten Modell, einem Evaluierungsbericht und einem FastAPI-Inference-Endpunkt, der auf Railway, Fly.io oder Hugging Face Spaces bereitgestellt ist. Ausstiegskriterien: Eine funktionierende Demo-URL, auf die jemand klicken kann, mit einem README, das Methodik und bekannte Einschränkungen erklär. Die bereitgestellte URL ist unverzichtbar — ein Notebook, das in Colab lebt, signalisiert unvollständige Arbeit.
Quartal 3 (Monate 7–9): Deep Learning + Spezialisierungswahl
Dies ist der Punkt, an dem Sie sich einer der drei Spezialisierungen von früher verpflichten. Hören Sie auf zu schwanken.
ML-Engineer-Weg: PyTorch-Grundlagen, Trainings-Schleifen, die Sie selbst schrieben (nicht Lightning), Grundlagen des verteilten Trainings (DDP), ein Kaggle-Medal-Versuch mit dokumentiertem Experiment.
LLM-Engineer-Weg: Hugging Face Transformers, LoRA und QLoRA Fine-Tuning auf einem Domänen-Datensatz, eine vollständige RAG-Pipeline mit einer Vector-Datenbank und ein LLM-Evaluierungs-Harness mit Promptfoo oder Ragas.
MLOps-Weg: Docker für ML-Workflows, Model Registries über MLflow, Drift-Überwachung mit Evidently oder Arize und CI/CD-Pipelines, die Modelle nach einem Zeitplan umschulen.
Portfolio-Meilenstein #2: Ein spezialisierungsspezifisches Projekt. Für LLM: Ein fein abgestimmtes Domain-Modell mit einer dokumentierten Evaluierungs-Suite, die mindestens 200 Prompts abdeckt. Für MLOps: Ein bereitgestelltes Modell mit Überwachungs-Dashboards und einem automatisierten Umschulungs-Auslöser.
Ein Framework tief zu lernen macht das zweite offensichtlich. Zwei Frameworks flach zu lernen macht Sie nützlich für keins.
Quartal 4 (Monate 10–12): Open Source, Networking, Interview-Vorbereitung
Täglicher Fokus: ein Open-Source-Beitrag (Hugging Face, LangChain, scikit-learn — beginnen Sie mit Dokumentations-PRs, um den Beitrag-Ablauf zu erlernen), zwei Kalt-Outreach-Nachrichten pro Tag und eine Interview-Vorbereitungs-Sitzung, die einen LeetCode-Medium mit ML-Systemdesign-Praxis kombiniert.
Portfolio-Meilenstein: ein akzeptierter PR zu einem erkannten Repository, plus ein unter-1.500-Wort technischer Write-up auf Ihrer persönlichen Website oder auf Substack über einen Kompromiss, den Sie in Ihren Portfolio-Projekten machten. Diese technischen Write-ups, die Suchsichtbarkeit aufbauen, sind die Artefakte, die Kalt-Recruiter-Outreach in warme Antworten umwandeln.
Ausstiegskriterien: Drei oder mehr aktive Recruiter-Gespräche, eine bezahlte Gig oder ein Open-Source-Maintainer-Referenz und einen poliertes Lebenslauf, der auf Ihre gewählte Spezialisierung ausgerichtet ist.
Eine Anmerkung zu Anpassungsfähigkeit als Meta-Skill: Das LLM-Ökosystem verschob sich dreimal 2024 — RAG, dann Agenten, dann Tool-Nutzung. Die Roadmap oben unterrichtet Sie die haltbare Schicht (Mathematik, Evaluierung, Bereitstellung), damit Sie die nächste Verschiebung absorbieren können, ohne von Grund auf neu zu beginnen. Die Kandidaten, die langfristig erfolgreich sind, sind nicht diejenigen, die diesen Jahrs Stack memorierten. Sie sind diejenigen, die das Urteil aufgebaut haben, nächsten Jahrs zu evaluieren.
Portfolio-Projekte, die Recruiter-Callbacks bringen
Ein Portfolio ist ein Einstellungs-Filter, nicht ein kreatives Ventil. Recruiter verbringen durchschnittlich sechs Sekunden auf einem Lebenslauf und ungefähr 90 Sekunden damit, ein GitHub durchzuklicken. Ihre Aufgabe: die ersten drei Projekte, die sie sehen, Produktionsbereitschaft signalisieren lassen, nicht hobbyistische Begeisterung. Gepinnte Repos zählen mehr als die Gesamtzahl der Repos.
| Projekttyp | Was es demonstriert | Bauzeit | Recruiter-Signal |
|---|---|---|---|
| Kaggle-Wettbewerb (top 25%) | Feature Engineering, Evaluierungs-Disziplin | 3-5 Wochen | Reproduzierbarkeit |
| End-to-End-ML-System | Produktions-Denken, Bereitstellung | 4-6 Wochen | Kann ausliefern, nicht nur trainieren |
| Fine-tuned LLM + eval suite | LoRA/QLoRA, Evaluierungs-Design, GenAI-Fließfertigkeit | 3-4 Wochen | Aktuelles Ökosystem |
| Open-Source-PR (akzeptiert) | Code-Review-Toleranz | 2-8 Wochen | Peer-bestätigte Qualität |
| Paper-Reimplementierung | Methoden-Verständnis | 6-10 Wochen | Akademische Tiefe (gemischt) |
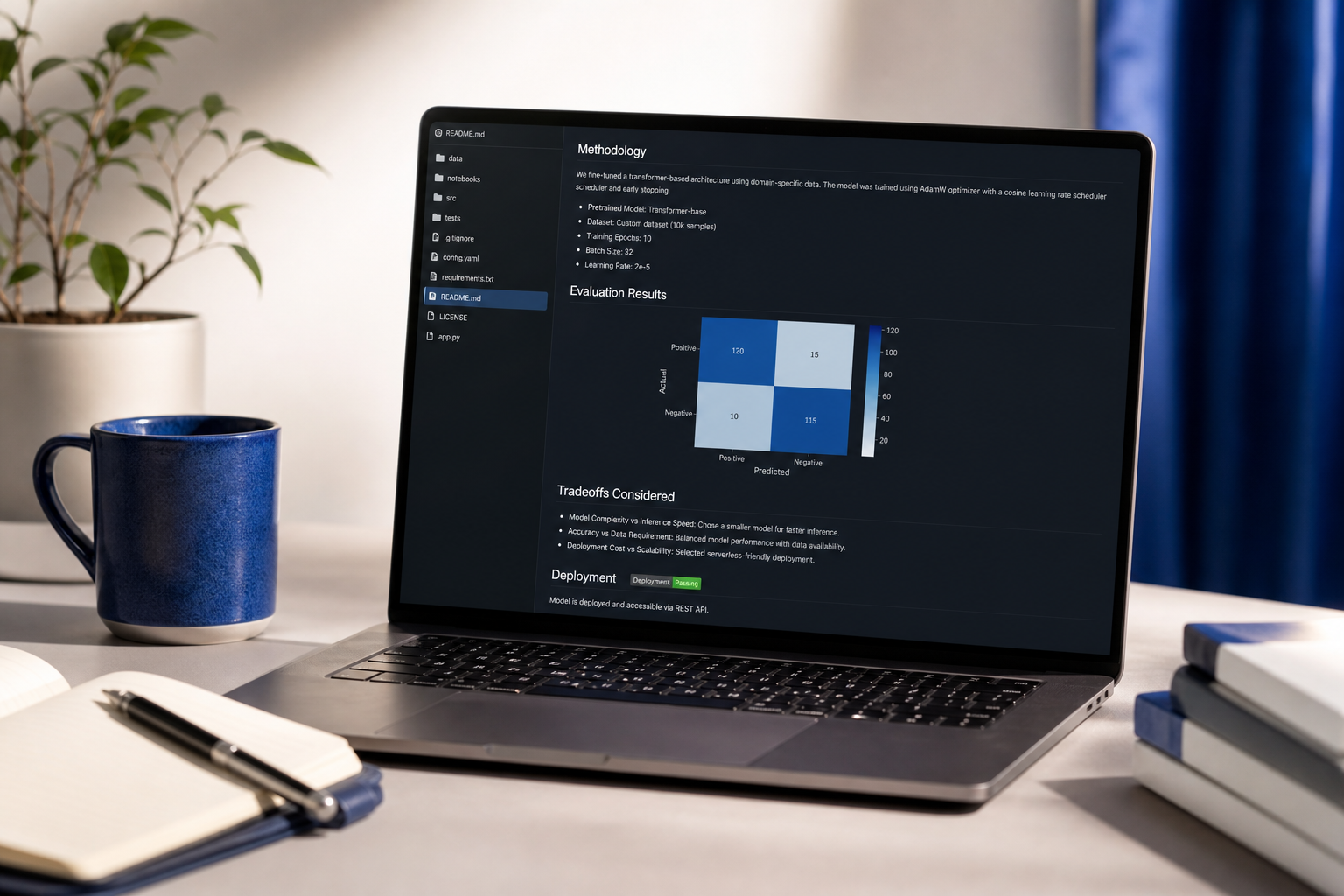
Breite schlägt Tiefe für Junior-Kandidaten. Drei mittlere-Komplexität-Projekte über verschiedene Domänen — eines tabellarisch ML, eines LLM, eines Bereitstellungs-fokussiert — signalisiert Bereich. Eine brillante Forschungs-Paper-Reimplementierung signalisiert „akademisch, liefert möglicherweise nicht aus." Einstellungsmanager bei produktgetriebenen Unternehmen lesen das zweite Profil und bestehen. Die Ausnahme: Wenn Sie auf Forschungslabore abzielen (Anthropic, DeepMind, FAIR), kehren Sie dies um — Tiefe gewinnt.
Die Evaluierungs-Rubrik ist das Projekt. Laut NIST-RMF-Richtlinien, zitiert früher, erfordern Produktions-KI-Systeme dokumentierte Evaluierungs-Schwellwerte. Ein Portfolio-Projekt ohne einen Evaluierungsbericht — Precision/Recall-Kurven, Fairness-Analyse über Subgruppen, Fehleranalyse auf fehlklassifizierten Beispielen — liest sich als unvollständig für Senior Engineers. Das Notebook ist der einfache Teil. Die Evaluierungs-Strenge ist der Differentiator.
Bereitstellung zählt mehr als Modell-Neuheit. Recruiter priorisieren zunehmend Kandidaten, die ein bereitgestelltes System zeigen können gegenüber denen mit höheren Kaggle-Rankings aber keinem ausgelieferten Code. Ein bescheidenes Modell hinter einer funktionierenden API schlägt ein raffiniertes Notebook, das niemals Colab verließ. Der Grund ist unsexy, aber praktisch: In Ihren ersten 90 Tagen im Job werden Sie ein v1-System ausliefern, nicht eine neue Architektur erfinden. Einstellungsmanager wollen Belege für die frühere.
Dokumentieren Sie die Kompromisse, die Sie ablehnten. Ein 500-Wort-README, das erklärt, warum Sie Random Forest über XGBoost wählten, warum Sie Kosinus-Ähnlichkeit über Punkt-Produkt in Ihrem RAG-Retrieval verwendeten, was Sie mit mehr Compute anders machen würden — das ist die Artefakt, die Interviews gewinnt. Es demonstriert das Urteil, das Einstellungsmanager aus einem Code-Review allein nicht testen können. Die meisten Kandidaten überspringen das, weil Schreiben schwärer ist als Codieren. Lehnen Sie sich in die Asymmetrie.
Das KI-Engineering-Toolkit: Was tatsächlich in der Produktion verwendet wird vs. Lebenslauf-Polsterung
Dieser Abschnitt ist absichtlich von Meinung geprägt. Das KI-Tool-Landschaftist laut, und die meisten LinkedIn-„Muss-Gelernt"-Listen wurden von Menschen geschrieben, die Kurse über diese exakten Tools verkaufen. Was folgt, ist das, was Produktionsteams tatsächlich 2026 ausführen.
Core ML Frameworks — PyTorch gewinnt für Neulerner. PyTorch dominiert neue Forschung und die meisten LLM-Tools (Hugging Face, vLLM, Axolotl) sind PyTorch-zuerst. TensorFlow bleibt dominant innerhalb von Google und in einigen Enterprise-Produktionsumgebungen, die vor 2022 gebaut wurden. Lernen Sie zuerst PyTorch. Wenn ein Zielauftrag TensorFlow erfordert, können Sie es in etwa drei Wochen abholen, sobald Sie die zugrunde liegende Tensor- und Autograd-Primitive verstehen.
LLM-Ökosystem — Hugging Face ist die Minimum-Anforderung, LangChain ist optional. Hugging Face Transformers, Datasets und der Hub sind 2026 unverzichtbar. LangChain wird weit verwendet, aber wird weit kritisiert für Überabstraktion — viele Produktionsteams haben sich nach Langchain-undichte Abstraktionen in Incident-Postmortems zu direkten API-Aufrufen mit benutzerdefinierter Orchestrierung verschoben. Lernen Sie genug LangChain, um Code anderer Leute zu lesen; ankern Sie Ihren ganzen Stack nicht daran. LlamaIndex ist die bessere Wahl für RAG-schwere Anwendungen. DSPy ist es wert zu beobachten, aber noch keine Einstellungs-Anforderung.
Resume-Polsterungs-Tools bringen Sie durch den Stichwort-Filter und werden in dem technischen Interview zerstoßen. Wählen Sie den Stack, den Sie unter Befragung verteidigen können.
Evaluierungs-Tools — der Differentiator, den die meisten Kandidaten überspringen. Das ist die Lücke, die Junior von Senior KI-Engineers in Interviews trennt, und der am meisten unterinvestierte Skill-Bereich in selbstgelehrten Roadmaps. Zu lernende Tools: Promptfoo oder Ragas für LLM-Evaluierung, Evidently AI für tabellarische Drift-Detektion, Weights & Biases für Experiment-Tracking. Laut Workflow-Analyse von unabhängigem Industrie-Analyst McKay Johns erfordern Produktions-KI-Systeme Evaluierungs-Protokolle, die mindestens 500 diverse Eingaben mit dokumentierten Fehler-Toleranzen testen. Wenn Sie fließend über Ihre Evaluierungs-Methodologie sprechen können, haben Sie sich bereits von der Mehrheit der Bewerber unterschieden.
Bereitstellungs-Stack — klein anfangen, K8s ist nicht das erste Problem Ihres neuen Mitarbeiters. Docker ist unverzichtbar. FastAPI zum Servieren. Modal, Replicate oder Hugging Face Inference Endpoints zum Model-Hosting ohne Infrastruktur-Schmerzen. Kubernetes ist genuin erforderlich bei Skalierung, aber die meisten KI-Engineering-Teams behandeln K8s als Plattform-Team-Territorium. K8s auf einem Junior-Lebenslauf ohne ein echtes Projekt, das es nutzte, aufzulisten, liest sich als Polsterung. Besseres Signal: Ein Dockerfile, das ein unter-2GB-Image mit richtigem Layer-Caching erzeugt.
Daten und Orchestrierung — pragmatische Wahl gewinnt. Pandas für unter-100GB-Datensätze. DuckDB für analytische Abfragen auf Parquet-Dateien (kriminell untergenutzt — es ist die effizienteste Stunde, die Sie investieren können). Polars, wenn Pandas langsam wird. Apache Spark nur, wenn Ihr Zielarbeitgeber explizit es ausführt. Für Orchestrierung ist Airflow incumbent; Prefect und Dagster gewinnen; wählen Sie basierend auf Stellenausschreibungs-Häufigkeit in Ihrem Zielmarkt. Für Vector Databases: pgvector, wenn Sie bereits Postgres ausführen, Pinecone, wenn Sie einen verwalteten Service heute brauchen, Weaviate, wenn Sie Open-Source mit Hybrid-Suche brauchen.
Wenn Sie ein neues Tool evaluieren, stellen Sie drei Fragen: Wird es von mindestens drei Unternehmen verwendet, bei dem Sie ein Angebot annehmen würden? Löst es ein Problem, das Sie wirklich getroffen haben, oder lernen Sie es präventiv? Wird es noch 18 Monate gepflegt? Die meisten „Muss-Gelernt-KI-Tools" auf LinkedIn fallen bei mindestens zwei dieser Checks durch. Das schnell verändernde Ökosystem belohnt Tiefe in wenigen stabilen Schichten, nicht Breite über dem Hype-Zyklus. Das ist wie wir KI-Tool-Haltbarkeit in angrenzenden Bereichen evaluieren auch — gleiches Prinzip, gleicher Filter.
Fähigkeiten in Angebote umwandeln: Das Netzwerk- und Interview-Spielbuch
Die meisten „wie man KI-Engineer wird"-Guides stoppen beim „Fähigkeiten aufbauen". Das ist die leichte Hälfte. Die schwierigere Hälfte — und die, die entscheidet, ob Sie im Monat 14 oder Monat 30 in KI arbeiten — ist Netzwerk und Interview-Narrativ. Einstellen ist ein Verteilungs-Problem, kein Meritokratie-Problem. Behandeln Sie es so.

1. Bauen Sie öffentlich, nicht im Verborgenen. Veröffentlichen Sie einen technischen Write-up pro Monat auf einer persönlichen Website, dev.to oder Substack. Teilen Sie auf LinkedIn dreimal pro Woche über das, was Sie aufbauen — nicht generische KI-Takes, sondern spezifische Lektionen aus Ihren Projekten. Laut der IEEE-Spectrum-Analyse, zitiert früher, ist der KI-Engineer-Talentmarkt laut; Sichtbarkeit ist ein Filter, den Recruiter verwenden, bevor sie sogar Ihren Lebenslauf öffnen. Wenn Sie keine Website noch haben, designen Sie eine persönliche Website mit einem KI-Workflow und überspringen Sie die zwei-wöchige WordPress-Umleitung.
2. Cold-Outreach 5 KI-Engineer pro Woche bei Zielunternehmen. Nicht Recruiter — Engineers. Stellen Sie eine spezifische Frage über ihren Tech Stack oder einen neueren Blog-Artikel, den sie schrieben. Konversionsrate zu einem Kaffee-Chat ist typischerweise ungefähr 10-15%, wenn die Nachricht wirklich spezifisch ist. Über 12 Wochen ergibt das ungefähr 6-9 Informations-Interviews — historisch die höchste Konversionsrate Top-of-Funnel für Engineering-Angebote. Generische Outreach konvertiert unter 2%. Der Unterschied ist, ihre Arbeit zu lesen, bevor Sie ihnen eine Nachricht senden.
3. Frame Portfolio-Projekte als gelöste Probleme, nicht als verwendete Tools. „Baute ein Betrugs-Erkennungsmodell" verliert gegen „Reduzierte False-Positive-Rate von 12% auf 4% auf einem 200.000-Transaktions-Datensatz, indem ich von logistischer Regression zu Gradient Boosting wechselte und drei engineered Features hinzufügte." Zahlen und Entscheidungen, nicht Technologie-Stacks. Recruiter scannen nach Ergebnissen; Engineers scannen nach Argumentationen. Beide wollen quantifizierte Resultate.
4. Bereiten Sie sich auf drei unterschiedliche Interview-Spuren vor. Codierung (LeetCode-Medium, überwiegend Arrays und Hashmaps für KI-Rollen — Sie brauchen keine hard Dynamic Programming), ML-Systemdesign (wie würden Sie YouTube-Empfehlungen aufbauen? wie würden Sie Drift in der Produktion entdecken?) und angewandtes ML (debug dieses Notebook, erkläre dieses Paper, kritisiere diese Evaluierungs-Methodologie). Verteilen Sie die Praxis-Zeit über alle drei. Die meisten Kandidaten overpreparen auf LeetCode und underpreparen auf Systemdesign — genau umgekehrt von dem, wo die Angebote gewonnen werden.
5. Verhandeln Sie Einstieg-Routen, nicht nur Angebote. Vertrags-zu-FTE-Umwandlung bei KI-nativen Startups wird zunehmend häufig. Das Annehmen eines dreimütigen bezahlten Vertrags mit einem festgeschriebenen FTE-Umwandlungspfad kann völlig den standardmäßigen Einstellungs-Funnel umgehen. Junior-Rollen bei Beratungen (Slalom, Thoughtworks, BCG GAMMA) geben 18 Monate Exposition zu vielfältigen KI-Projekten bei niedrigerem Anfangs-Comp — wiegen Sie Lern-Geschwindigkeit gegen Comp explizit ab. Die Rolle, die Ihre Fähigkeits-Trajektorie bei Monat 24 maximiert, ist oft nicht das höchste erste-Jahr-Angebot.
6. Nehmen Sie an zwei Communitys teil, nicht an sieben. Wählen Sie einen Slack oder Discord (MLOps Community, Latent Space, Hugging Face Discord) und ein persönlich-vor-Ort Community (lokales KI-Meetup, eine Konferenz pro Jahr). Tiefe der Präsenz in zwei Communities schlägt Lurking in sieben. Menschen empfehlen Kandidaten, die sie erkennen. Erkennung erfordert konsistente, beitragende Präsenz — Fragen beantworten, Projekt-Updates teilen, an Office Hours teilnehmen.
7. Verfolgen Sie Ihre Jobsuche wie eine Pipeline. Outreach gesendet, Antworten erhalten, Anrufe geplant, Take-Homes erhalten, On-Sites, Angebote. Überprüfen Sie wöchentlich. Wenn die Antwortquote unter 8% liegt, Ihr Lebenslauf oder Ihre Outreach-Nachricht braucht Überarbeitung, bevor mehr Volumen hilft. Wenn Take-Home-zu-On-Site-Konversion niedrig ist, Ihre Code-Dokumentation ist der Bottleneck. Wenn On-Site-zu-Angebot niedrig ist, Ihre Interview-Vorbereitung braucht Arbeit. Debug den Funnel, wo er undicht ist — gleiche Evaluierungs-Disziplin, die Sie auf Ihre Modelle anwendeten.
Sogar starke Kandidaten mit ausgelieferten Portfolios brauchen typischerweise 3–5 Monate aktive Suche, um 2026 Ihre erste KI-Engineer-Rolle zu landen. Die Messlatte ist hoch, weil die Decke hoch ist. Die Kandidaten, die Angebote landen, sind diejenigen, die die Suche selbst als System zum Debuggen behandeln — nicht als Lotterie zum Betreten. Für mehr Rahmen zum Aufbau haltbarer Karriere- und Produktsysteme, aymartech veröffentlicht angrenzend Spielbücher wert zum Lesezeichen.
Häufig gestellte Fragen zum Werden eines KI-Engineers im Jahr 2026
Brauche ich einen CS-Grad, um KI-Engineer zu werden?
Nein — aber Sie müssen das kompensieren, was der Grad signalisiert. Ein CS-Grad gibt Recruitern einen schnellen Kompetenzen-Proxy: Datenstrukturen, Systems-Denken, algorithmische Intuition. Ohne ihn trägt Ihr Portfolio die volle Signalisierungs-Last. Selbstgelehrte Engineers, die Rollen landen, haben typischerweise einen starken Open-Source-Beitrag, der Code-Review-Toleranz zeigt, ein bereitgestelltes End-to-End-Projekt mit einer funktionierenden URL und demonstratives Systems-Wissen (Docker, basis Networking, SQL). Laut der CMU-SEI-Analyse ist die Lücke selten Berechtigungen — es ist Evaluierungs-Strenge und Produktionsdisziplin. Der Non-CS-Weg addiert ungefähr 4–6 Monate Timeline versus einem CS-Absolventen, der den gleichen Übergang macht. Es ist nicht geschlossen. Es ist länger, und die Messlatte für Portfolio-Qualität ist höher.
Was ist der tatsächliche Unterschied zwischen einem Data Scientist und einem KI-Engineer?
Data Scientists beantworten Geschäftsfragen mit statistischen Modellen — schwer auf Experimentierung, Präsentationen und Stakeholder-Kommunikation. KI-Engineers liefern Systeme aus — schwer auf Produktionscode, Bereitstellung und Überwachung. Data Scientists arbeiten typischerweise in Jupyter Notebooks; KI-Engineers arbeiten in IDEs mit versionskontrolliertem Produktionscode. Die Vergütung divergiert entsprechend: Training-Industrie-Daten setzen KI-Engineer-Gehaltsspannen auf $130K-$250K+ versus $96K-$150K für Data Scientists in den USA. Die Rollen überlappen zunehmend bei kleinen Startups, aber trennen sich scharf bei Unternehmen vorbei 200 Mitarbeitern. Wenn Sie Code ausliefern mehr als Erkenntnisse präsentieren genießen, zielen auf KI-Engineer.
Sollte ich einen Master-Grad verfolgen oder Selbststudium?
Selbststudium funktioniert für die meisten Wege in KI-Engineering und spart ungefähr $40.000-$120.000 in Unterricht. Ein Master ist in drei spezifischen Fällen wert: Sie brauchen ein US-Work-Visum und der Grad ist Ihr Immigrations-Weg; Sie zielen auf Forschungsrollen bei Industrie-Laboren (DeepMind, Anthropic, FAIR), wo Berechtigungen noch Gewicht tragen; oder Sie wechseln aus einem Feld mit keinem quantitativen Track-Record auf Papier. Andernfalls, die 18–24-Monats-Gelegenheits-Kosten eines Masters übertrifft typischerweise den Berechtigungs-Vorteil — besonders im Vergleich zu einem starken Portfolio, das in der gleichen Zeitraum ohne Unterricht-Laster gebaut wurde. Die Ausnahme wert zu überlegen: Teil-Zeit-Online-Programme wie Georgia Tech OMSCS, die unter $10K kosten und dich nicht aus dem Jobmarkt ziehen.
Wie beeinflussen Regulierung (EU-KI-Gesetz, NIST-KI-RMF) KI-Engineer-Einstellen auf Junior-Ebene?
Es erweitert Einstellen, nicht kontrahiert es. Regulierungsanforderungen schaffen Nachfrage nach Engineers, die Audit-Spuren bauen, Trainings-Daten-Provenance dokumentieren und Bias-Test-Schwellwerte implementieren können. Kandidaten, die fließend über Compliance-Anforderungen sprechen können — sogar auf Junior-Ebene — differenzieren stark in regulierten Industrien wie Finanzen, Gesundheitswesen und öffentlicher Sektor. Das NIST-RMF einmal vor Interviews zu lesen setzt dich vor die Mehrheit der Junior-Kandidaten, die Compliance als jemand anders Problem behandeln. In der Praxis, Kandidaten, die Modellierungs-Geschick mit Regulierungs-Literalität koppeln, befehlen einen Premium in Gesundheitswesen und Fintech spezifisch — jene Teams können nicht ohne diese Kombination ausliefern, und Angebot ist dünn.