
Comment devenir ingénieur en IA en 2026 : compétences, feuille de route et outils
Trois rôles d'ingénieur IA qui paient six chiffres — Et lequel correspond à votre profil

Vous lisez ceci parce que vous avez déjà fait les calculs sur les salaires des ingénieurs IA — 130 K$ à 250 K$+ aux États-Unis selon les données de rémunération de l'industrie de la formation de Dataquest — et vous voulez savoir ce qu'il faut vraiment faire pour y arriver. Le Bureau américain des statistiques du travail projette une croissance de 35% pour les chercheurs en informatique et en systèmes d'information (la catégorie qui inclut les rôles en IA) de 2022 à 2032, bien au-dessus de la moyenne de 4% pour toutes les professions, selon le BLS. L'opportunité est réelle. Tout comme la question de savoir comment être ingénieur IA quand la moitié d'Internet vous vend un bootcamp.
C'est ici que ça devient inconfortable. Une analyse IEEE Spectrum des offres d'emploi de 2025 a révélé que 68% des postes étiquetés « Ingénieur IA » décrivent en réalité de l'ingénierie logicielle avancée avec un travail minimal spécifique à l'IA, selon IEEE Spectrum. Traduction : plus de la moitié des offres auxquelles vous postulez ne veulent pas ce que le titre dit qu'elles veulent. L'inflation des titres est le secret le moins bien gardé du marché.
Cet article ne prétend pas que vous serez embauché en 90 jours. Il vous donne la séquence réelle — quelle spécialisation choisir, quels fondements sont importants (et lesquels sauter), comment construire un portfolio qui survit au clic GitHub d'un ingénieur senior, et comment convertir les compétences en offres. Aucun lien d'affiliation bootcamp. Aucune hype.
Table des matières
- Trois rôles d'ingénieur IA qui paient six chiffres — Et lequel correspond à votre profil
- Compétences fondamentales qui vous font vraiment embaucher (Et la théorie que vous pouvez sauter)
- La feuille de route de 12 mois pour ingénieur IA : Une séquence trimestrielle
- Projets de portfolio qui obtiennent vraiment des rappels de recruteurs
- La boîte à outils de l'ingénieur IA : Ce qui est réellement utilisé en production vs. Rembourrage de CV
- Convertir les compétences en offres : Le manuel du réseautage et des entretiens
- Questions courantes sur la façon de devenir ingénieur IA en 2026
Trois rôles d'ingénieur IA qui paient six chiffres — Et lequel correspond à votre profil
« Ingénieur IA » est maintenant un terme générique. Les responsables du recrutement chez Anthropic, Stripe et Mayo Clinic recherchent trois profils distincts, et les compétences requises divergent fortement après le troisième mois d'apprentissage. Choisissez-en un avant de choisir un manuel. Choisir tard signifie réapprendre une pile de frameworks différente au septième mois — c'est la raison la plus courante pour laquelle les changements de carrière s'épuisent.
Ingénieur ML. Entraîne les modèles, conçoit des expériences, met à l'échelle les pipelines d'entraînement. Mathématiques lourdes : algèbre linéaire, probabilité, théorie de l'optimisation. C'est le chemin dans les entreprises ayant des actifs de données propriétaires — recommandations Netflix, classement Spotify, fraude Stripe. Vous passerez plus de temps sur l'ingénierie des caractéristiques et la rigueur d'évaluation que sur la construction de systèmes orientés utilisateurs. Ajustement fort pour les formations en informatique, statistiques, physique ou mathématiques appliquées.
Ingénieur LLM/GenAI. Crée des applications sur les modèles de fondation. Lourd sur l'ingénierie des invites, la génération augmentée par récupération (RAG), les appareils d'évaluation et l'ajustement fin économe en paramètres avec LoRA ou QLoRA. Courant dans les startups natives IA et les équipes d'entreprise expédiant des copilotes internes. La spécialisation qui connaît la croissance la plus rapide dans l'embauche de 2025. Ajustement fort pour les ingénieurs de produit et les ingénieurs logiciels full-stack — vous savez déjà comment expédier ; vous apprenez la couche de modélisation.
Ingénieur systèmes IA / MLOps. Possède le déploiement, la surveillance et la fiabilité de l'infrastructure. Lourd sur Docker, Kubernetes, la diffusion de modèles (Triton, BentoML) et les outils d'observabilité (Weights & Biases, Arize). Courant dans les industries réglementées — finance, santé, secteur public — où la stabilité en production importe plus que la modélisation nouvelle. Ajustement fort pour les ingénieurs backend, DevOps et ingénieurs de fiabilité des sites ajoutant le cycle de vie du modèle à leur ensemble d'outils existant.
| Rôle | Profondeur mathématique | Outils primaires | Gamme de salaire typique (États-Unis) | Meilleur profil d'entrée |
|---|---|---|---|---|
| Ingénieur ML | Profonde | PyTorch, scikit-learn, Spark | 128 K$–220 K$+ | Informatique, statistiques, physique |
| Ingénieur LLM/GenAI | Modérée | Hugging Face, LangChain, LoRA, DBs vectorielles | 130 K$–250 K$+ | Ingénierie logicielle |
| Ingénieur systèmes IA / MLOps | Légère (niveau système) | Docker, K8s, Triton, MLflow, W&B | 135 K$–230 K$+ | Backend, DevOps, SRE |
Les gammes salariales proviennent des données de rémunération de l'industrie de la formation Dataquest — vérifiez sur Levels.fyi pour les gammes d'offres spécifiques.
Le marché ne récompense pas encore les généralistes. Il récompense les spécialistes qui peuvent livrer un système fonctionnant dans leur domaine dans les quatre-vingt-dix jours suivant l'embauche.
Selon le Rapport d'indice IA 2025 de Stanford HAI, 56% des entreprises disposent maintenant de rôles d'ingénierie IA dédiés, contre 32% en 2023. La spécialisation LLM/GenAI croît le plus rapidement dans l'embauche d'entreprise, mais la piste MLOps a le taux de conversion d'offre le plus élevé car l'offre est véritablement contrainte — les ingénieurs backend qui ont acquis une profondeur MLOps sont plus rares que les débutants fraîchement entraînés en LLM.
Croisez ceci avec la découverte IEEE sur l'inflation des rôles. Le filtre ayant le plus grand effet de levier que vous pouvez appliquer à votre recherche d'emploi n'est pas le titre — c'est d'adapter votre spécialisation au travail réel décrit dans une offre. Lisez la section des responsabilités. Si un rôle « Ingénieur IA principal » liste « concevoir des API RESTful, optimiser les requêtes PostgreSQL et intégrer avec les webhooks Stripe », c'est un rôle backend avec des termes à la mode IA. Passez.
Compétences fondamentales qui vous font vraiment embaucher (Et la théorie que vous pouvez sauter)
La plupart des feuilles de route d'ingénieur IA commencent par six mois de calcul multivariable et théorie de la mesure. Vous n'avez pas besoin de cela pour être embauché. Vous avez besoin d'une compréhension fonctionnelle de cinq domaines — assez pour lire un article, déboguer un modèle et expliquer un compromis dans un entretien. Le Dr Michael Chen de l'Institut d'ingénierie logicielle de CMU a analysé 500 référentiels GitHub d'ingénieurs IA autodidactes et a trouvé que seulement 12% implémentaient des cadres d'évaluation appropriés, selon CMU SEI. L'écart qui tue les offres n'est presque jamais « plus de mathématiques ». C'est la discipline de production.

Algèbre linéaire et calcul — seulement le sous-ensemble fonctionnel. Vous avez besoin de : opérations matricielles (multiplication, inverse, transposition), valeurs propres et vecteurs propres à un niveau intuitif, gradients et règle de chaîne, distributions de probabilité de base. Vous pouvez sauter : analyse réelle, théorie de la mesure, preuves formelles. La série YouTube gratuite « Essence of Linear Algebra » de 3Blue1Brown couvre environ 80% des connaissances fonctionnelles en environ quatre heures. Si vous pouvez dériver la rétropropagation sur papier pour un réseau à deux couches, vous avez assez.
Python — l'écosystème IA, pas seulement le langage. Au-delà de la syntaxe : diffusion de tableaux NumPy, Pandas groupby, fusion et opérations de séries chronologiques, tenseurs PyTorch et autograd, async/await pour le travail API, et empaquetage moderne avec Poetry ou uv. Les responsables du recrutement testent les compréhensions de listes, les décorateurs et les gestionnaires de contexte lors des écrans techniques — pas les énigmes algorithmiques que vous verriez lors d'un entretien FAANG. Devenez fluide en Python idiomatique avant de toucher un modèle.
Statistiques et conception de l'évaluation. Test d'hypothèse, intervalles de confiance, conception de test A/B avec calcul de taille d'échantillon et correction de comparaisons multiples, et métriques d'évaluation de modèle allant au-delà de la précision : compromis précision/rappel, courbes ROC/AUC, calibrage, scores BLEU et ROUGE pour le texte, et évaluation spécifique à LLM (LLM-as-judge, jeux de données dorés, rappel de récupération@k). Selon le Cadre de gestion des risques IA du NIST, les systèmes en production devraient tester au minimum sur un ensemble d'évaluation organisé avec seuils de biais documentés et de performance. Si votre projet de portfolio manque d'un rapport d'évaluation, il se lit comme incomplet.
SQL et préparation des données — indispensable, même pour les ingénieurs LLM. Chaque système IA en production extrait d'une base de données. Vous avez besoin de : jointures (interne, gauche, fonctions de fenêtre), CTE, optimisation des requêtes (indices, plans EXPLAIN), et au moins une base de données vectorielle — pgvector, Pinecone, ou Weaviate — pour le travail RAG. Ignorez Hadoop entièrement. Apprenez Spark uniquement si vos offres d'emploi cibles mentionnent explicitement. DuckDB est le joyau sous-estimé qui vaut deux week-ends d'étude.
Git, Docker et une plateforme cloud. Stratégies de branchement (trunk-based ou GitHub Flow), écrire des Dockerfiles qui ne produisent pas 8 Go de bloat d'image, et déployer sur AWS, GCP ou Azure. Vous n'avez pas besoin de Kubernetes pour votre premier rôle. La plupart des équipes d'ingénierie IA traitent K8s comme un territoire d'équipe de plateforme, pas la responsabilité de l'ingénieur de modélisation. Lister K8s sur votre CV sans un vrai projet l'utilisant se lit comme du rembourrage de CV pour les interviewers expérimentés.
L'objectif n'est pas une thèse en informatique complète. C'est assez de fluidité pour expédier. Si vous pouvez entraîner un modèle, l'évaluer sur un ensemble retenu, le déployer derrière un point final FastAPI, et défendre votre méthodologie d'évaluation dans un entretien — vous avez franchi la barre pour la grande majorité des rôles d'ingénieur IA au niveau d'entrée.
La feuille de route de 12 mois pour ingénieur IA : Une séquence trimestrielle
Les fournisseurs de formation comme Dataquest suggèrent qu'un ingénieur logiciel peut faire la transition en 3-5 mois — étiquetez-le comme une estimation de fournisseur, pas un consensus industriel. L'analyse CMU SEI suggère que ce délai est irréaliste pour un travail de qualité en production pour quelqu'un partant de zéro. Le délai réaliste : environ 12 mois à temps partiel (15-20 heures par semaine) pour un profil non-informatique pour atteindre la compétence embaucheble, environ 6-8 mois pour un ingénieur logiciel travaillant ajoutant une spécialisation IA. Cette feuille de route suppose le chemin plus long. Comprimez à vos risques et périls.

Trimestre 1 (Mois 1–3) : Python de base + Rafraîchissement mathématique + Premier notebook expédié
Foyer quotidien : 60% pratique Python, Pandas et NumPy, 30% algèbre linéaire via 3Blue1Brown et Khan Academy, 10% lecture des offres d'emploi d'ingénierie IA pour internaliser ce que « prêt » signifie sur votre marché cible. La lecture des offres n'est pas de la procrastination — c'est de la recherche de marché.
Ressources gratuites recommandées : Cours d'apprentissage profond pratique fast.ai 1, piste « Intro to Machine Learning » de Kaggle, et Cours NLP Hugging Face. Les trois sont véritablement gratuits et construits par des praticiens qui livrent.
Étape du portfolio : Une entrée de compétition Kaggle avec un notebook public documentant vos décisions d'ingénierie des caractéristiques et rationnelle du choix du modèle. Critères de sortie : vous pouvez charger un CSV, entraîner un modèle scikit-learn de base, l'évaluer sur un ensemble retenu, et expliquer en un paragraphe pourquoi vous avez choisi votre métrique d'évaluation par rapport aux alternatives.
Trimestre 2 (Mois 4–6) : Fondamentaux ML + Premier projet de bout en bout
Foyer quotidien : plongée profonde scikit-learn, rigueur d'évaluation des modèles, intro à PyTorch. Sujets importants : régularisation, validation croisée, réglage des hyperparamètres, pourquoi votre ensemble de test a fui (ce sera le cas), et calibrage. Le mode d'échec le plus courant pour les ingénieurs autodidactes : performances sur l'ensemble d'entraînement qui ne survivent pas au contact avec des données d'attente réelles.
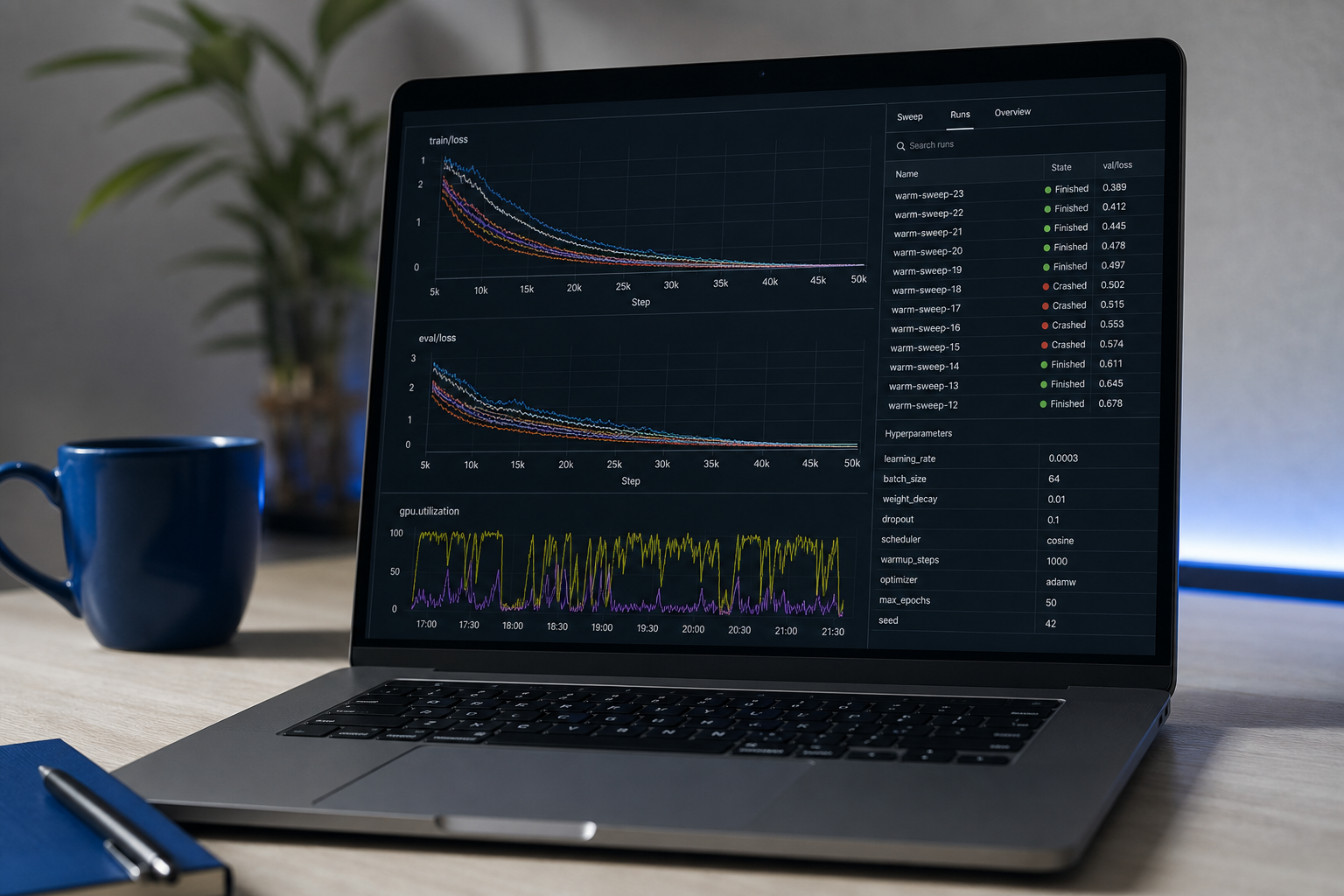
Étape du portfolio #1 : Un projet de bout en bout avec données nettoyées, un modèle entraîné, un rapport d'évaluation et un point final d'inférence FastAPI déployé sur Railway, Fly.io, ou Hugging Face Spaces. Critères de sortie : une URL de démonstration fonctionnelle sur laquelle quelqu'un peut cliquer, avec un README expliquant la méthodologie et les limitations connues. L'URL déployée est non-négociable — un notebook qui vit dans Colab signale un travail incomplet.
Trimestre 3 (Mois 7–9) : Apprentissage profond + Choix de spécialisation
C'est là que vous vous engagez dans l'une des trois spécialités d'auparavant. Arrêtez de vous couvrir.
Chemin ingénieur ML : Fondamentaux PyTorch, boucles d'entraînement que vous avez vous-même écrites (pas Lightning), bases de l'entraînement distribué (DDP), une tentative de médaille Kaggle avec expérimentation documentée.
Chemin ingénieur LLM : Hugging Face Transformers, ajustement fin LoRA et QLoRA sur un jeu de données de domaine, un pipeline RAG complet avec une base de données vectorielle, et un appareil d'évaluation LLM utilisant Promptfoo ou Ragas.
Chemin MLOps : Docker pour les workflows ML, registres de modèles via MLflow, surveillance de la dérive avec Evidently ou Arize, et pipelines CI/CD qui réentraînent les modèles sur un calendrier.
Étape du portfolio #2 : Un projet spécifique à la spécialisation. Pour LLM : un modèle de domaine affiné avec une suite d'évaluation documentée couvrant au minimum 200 invites. Pour MLOps : un modèle déployé avec tableaux de bord de surveillance et un déclencheur de réentraînement automatisé.
Apprendre un framework en profondeur rend le deuxième évident. Apprendre deux frameworks superficiellement vous rend utile pour aucun.
Trimestre 4 (Mois 10–12) : Open Source, réseautage, préparation aux entretiens
Foyer quotidien : une contribution open-source (Hugging Face, LangChain, scikit-learn — commencez par les RP de documentation pour apprendre le flux de contribution), deux messages de sensibilisation à froid par jour, et une session de préparation aux entretiens combinant un LeetCode moyen avec pratique de conception du système ML.
Étape du portfolio : une RP acceptée dans un référentiel reconnu, plus un article technique de moins de 1 500 mots sur votre site personnel ou Substack sur un compromis que vous avez rencontré dans vos projets de portfolio. Ces articles techniques qui construisent une visibilité SEO sont l'artefact qui convertit la sensibilisation à froid du recruteur en réponses chaleureuses.
Critères de sortie : trois ou plus des conversations de recruteur actives, une référence de mainteneur de contrat payant ou open-source, et un CV poli aligné sur votre spécialisation choisie.
Une note sur l'adaptabilité en tant que méta-compétence : l'écosystème LLM a changé trois fois en 2024 — RAG, puis agents, puis utilisation d'outils. La feuille de route ci-dessus vous enseigne la couche durable (mathématiques, évaluation, déploiement) afin que vous puissiez absorber le prochain changement sans redémarrer à zéro. Les candidats qui prospèrent à long terme ne sont pas ceux qui ont mémorisé la pile de cette année. Ce sont ceux qui ont développé le jugement pour évaluer la pile de l'année prochaine.
Projets de portfolio qui obtiennent vraiment des rappels de recruteurs
Un portfolio est un filtre d'embauche, pas une sortie créative. Les recruteurs passent en moyenne six secondes sur un CV et environ 90 secondes en cliquant dans GitHub. Votre travail : faire en sorte que les trois premiers projets qu'ils voient signalent la disponibilité en production, pas l'enthousiasme de hobbyiste. Les référentiels épinglés importent plus que le nombre total de référentiels.
| Type de projet | Ce qu'il démontre | Temps de construction | Signal de recruteur |
|---|---|---|---|
| Compétition Kaggle (top 25%) | Ingénierie des caractéristiques, discipline d'évaluation | 3-5 semaines | Reproductibilité |
| Système ML de bout en bout | Pensée en production, déploiement | 4-6 semaines | Peut expédier, pas seulement entraîner |
| LLM affiné + suite d'éval | LoRA/QLoRA, conception d'éval, fluidité GenAI | 3-4 semaines | Écosystème actuel |
| RP open-source (acceptée) | Tolérance à l'examen de code | 2-8 semaines | Qualité validée par les pairs |
| Réimplémentation de papier | Compréhension de la méthode | 6-10 semaines | Profondeur académique (mixte) |
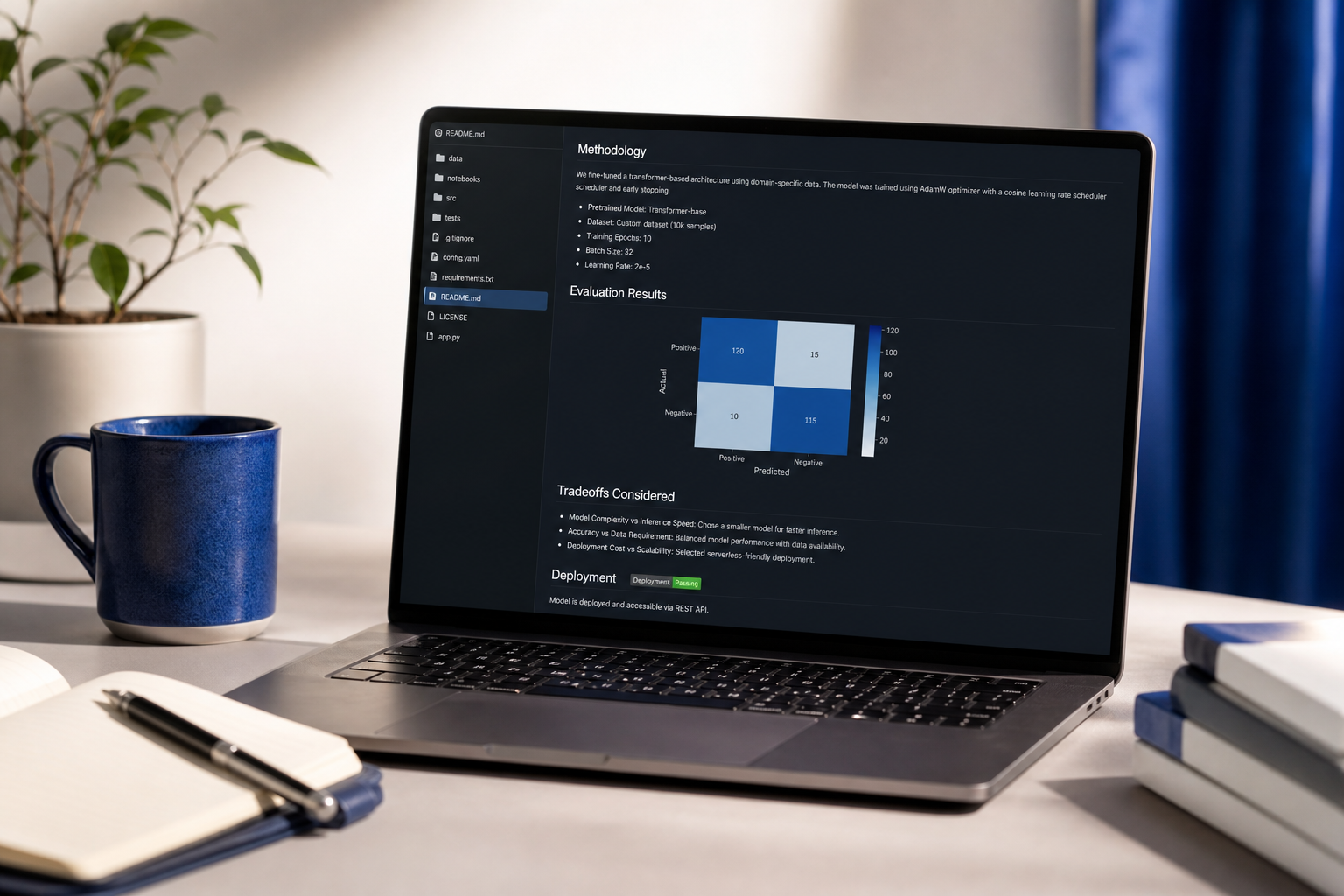
L'ampleur bat la profondeur pour les candidats au niveau d'entrée. Trois projets de complexité moyenne dans différents domaines — un ML tabulaire, un LLM, un axé sur le déploiement — signale la gamme. Une brillante réimplémentation de papier de recherche signale « académique, peut ne pas expédier ». Les responsables du recrutement chez les entreprises orientées produit lisent le deuxième profil et passent. L'exception : si vous ciblez des laboratoires de recherche (Anthropic, DeepMind, FAIR), inversez ceci — la profondeur gagne.
Le rubrique d'évaluation est le projet. Selon les directives du NIST AI RMF citées auparavant, les systèmes IA en production nécessitent des seuils d'évaluation documentés. Un projet de portfolio sans rapport d'évaluation — courbes précision/rappel, analyse d'équité entre sous-groupes, analyse d'erreur sur les exemples mal classifiés — se lit comme incomplet pour les ingénieurs senior. Le notebook est la partie facile. La rigueur d'éval est le différenciateur.
Le déploiement importe plus que la nouveauté du modèle. Les recruteurs donnent de plus en plus la priorité aux candidats qui peuvent montrer un système déployé par rapport à ceux ayant des classements Kaggle plus élevés mais pas de code expédié. Un modèle modeste derrière une API fonctionnelle bat un notebook sophistiqué qui n'a jamais quitté Colab. La raison est peu glamour mais pratique : dans vos 90 premiers jours d'emploi, vous allez expédier un système v1, pas inventer une nouvelle architecture. Les responsables du recrutement veulent une preuve du premier, pas du second.
Documentez les compromis que vous avez rejetés. Un README de 500 mots expliquant pourquoi vous avez choisi Random Forest plutôt que XGBoost, pourquoi vous avez utilisé la similarité cosinus plutôt que le produit scalaire dans votre récupération RAG, ce que vous feriez différemment avec plus de calcul — c'est l'artefact qui gagne les entretiens. Il démontre le jugement que les responsables du recrutement ne peuvent pas tester à partir d'une revue de code seule. La plupart des candidats le sautent parce que l'écriture est plus difficile que le codage. Penchez-vous dans l'asymétrie.
La boîte à outils de l'ingénieur IA : Ce qui est réellement utilisé en production vs. Rembourrage de CV
Cette section est délibérément opinée. Le paysage des outils IA est bruyant, et la plupart des listes « à apprendre absolument » sur LinkedIn sont écrites par des personnes vendant des cours sur ces outils exactement. Ce qui suit est ce que les équipes en production exécutent réellement en 2026.
Frameworks ML de base — PyTorch gagne pour les nouveaux apprenants. PyTorch domine la nouvelle recherche et la plupart des outils LLM (Hugging Face, vLLM, Axolotl) est d'abord PyTorch. TensorFlow reste dominant à l'intérieur de Google et dans certains environnements de production d'entreprise construits avant 2022. Apprenez PyTorch d'abord. Si un emploi cible nécessite TensorFlow, vous pouvez le prendre en environ trois semaines une fois que vous comprenez les primitives de tenseur et autograd sous-jacentes.
Écosystème LLM — Hugging Face est le minimum, LangChain est optionnel. Hugging Face Transformers, Datasets et le Hub sont non-négociables en 2026. LangChain est largement utilisé mais largement critiqué pour sur-abstraction — de nombreuses équipes en production ont migré vers les appels d'API directs avec orchestration personnalisée après avoir heurté les abstractions qui fuient de LangChain dans les post-mortems d'incidents. Apprenez assez LangChain pour lire le code des autres gens ; n'ancrez pas votre pile entière dessus. LlamaIndex est le meilleur choix pour les applications lourdes en RAG. DSPy vaut la peine de regarder mais n'est pas encore une exigence d'embauche.
Les outils de rembourrage de CV vous font passer le filtre de mot-clé et vous écrasent dans l'entretien technique. Choisissez la pile que vous pouvez défendre sous le questionnement.
Outils d'évaluation — le différenciateur que la plupart des candidats sautent. C'est l'écart qui sépare les ingénieurs IA senior des juniors dans les entretiens, et la zone de compétence sous-investie la plus importante dans les feuilles de route autodidactes. Outils à apprendre : Promptfoo ou Ragas pour l'évaluation LLM, Evidently AI pour la détection de dérive tabulaire, Weights & Biases pour le suivi des expériences. Selon l'analyse du flux de travail d'un analyste industriel indépendant McKay Johns, les systèmes IA en production nécessitent des protocoles d'évaluation testant un minimum de 500 entrées diverses avec tolérances d'erreur documentées. Si vous pouvez parler couramment de votre méthodologie d'évaluation, vous vous êtes déjà séparé de la plupart des candidats.
Pile de déploiement — commencez petit, K8s n'est pas le problème de votre première embauche. Docker est essentiel. FastAPI pour servir. Modal, Replicate, ou Hugging Face Inference Endpoints pour l'hébergement de modèles sans douleur d'infrastructure. Kubernetes est véritablement requis à grande échelle, mais la plupart des équipes d'ingénierie IA traitent K8s comme un territoire d'équipe de plateforme. Lister K8s sur un CV junior sans un vrai projet l'utilisant se lit comme du rembourrage. Meilleur signal : un Dockerfile qui produit une image sous-2GB avec cache de couche approprié.
Données et orchestration — les choix pragmatiques gagnent. Pandas pour les jeux de données sous 100 Go. DuckDB pour les requêtes analytiques sur les fichiers Parquet (criminellement sous-utilisé — c'est l'heure la plus efficace que vous pouvez investir). Polars quand Pandas devient lent. Apache Spark seulement si votre employeur cible l'exécute explicitement. Pour l'orchestration, Airflow est le titulaire ; Prefect et Dagster gagnent du terrain ; choisissez en fonction de la fréquence d'offre d'emploi sur votre marché cible. Pour les bases de données vectorielles : pgvector si vous exécutez déjà Postgres, Pinecone si vous avez besoin d'un service géré aujourd'hui, Weaviate si vous avez besoin d'open-source avec recherche hybride.
Lors de l'évaluation de tout nouvel outil, posez-vous trois questions : Est-il utilisé par au moins trois entreprises où vous accepteriez une offre ? Résout-il un problème que vous avez réellement heurté, ou apprenez-vous préventivement ? Sera-t-il toujours maintenu dans 18 mois ? La plupart des « outils IA à apprendre absolument » sur LinkedIn échouent au moins deux de ces vérifications. L'écosystème qui change rapidement récompense la profondeur dans quelques couches stables, pas l'ampleur à travers le cycle du battage médiatique. C'est comment nous évaluons la durabilité des outils IA dans les domaines adjacents aussi — même principe, même filtre.
Convertir les compétences en offres : Le manuel du réseautage et des entretiens
La plupart des guides « comment être ingénieur IA » s'arrêtent à « construire des compétences ». C'est la moitié facile. La moitié la plus difficile — et celle qui décide si vous travaillez en IA au mois 14 ou au mois 30 — est le réseautage et la narration d'entretien. L'embauche est un problème de distribution, pas une méritocratie. Traitez-le comme tel.

1. Construisez publiquement, pas en secret. Publiez un article technique par mois sur un site personnel, dev.to ou Substack. Partagez sur LinkedIn trois fois par semaine à propos de ce que vous construisez — pas des prises génériques sur l'IA, mais des leçons spécifiques de vos projets. Selon l'analyse IEEE Spectrum citée auparavant, le marché des talents d'ingénieur IA est bruyant ; la visibilité est un filtre que les recruteurs utilisent avant même d'ouvrir votre CV. Si vous n'avez pas encore de site, concevez un site personnel en utilisant un flux de travail IA et ignorez le détour WordPress de deux semaines.
2. Sensibilisez 5 ingénieurs IA par semaine dans les entreprises cibles. Pas les recruteurs — les ingénieurs. Posez une question spécifique sur leur pile technologique ou un article de blog récent qu'ils ont écrit. Le taux de conversion à un café est généralement d'environ 10-15% quand le message est véritablement spécifique. Sur 12 semaines, cela donne environ 6-9 entretiens informatifs — historiquement l'entonnoir supérieur avec le taux de conversion le plus élevé pour les offres d'ingénierie. La sensibilisation générique convertit à moins de 2%. La différence est de lire leur travail avant de leur envoyer un message.
3. Encadrez les projets de portfolio comme des problèmes résolus, pas des outils utilisés. « Créé un modèle de détection de fraude » perd contre « Réduit le taux de faux positif de 12% à 4% sur un jeu de données de 200 K transactions en passant de la régression logistique au boosting de gradient et en ajoutant trois caractéristiques d'ingénierie ». Chiffres et décisions, pas piles technologiques. Les recruteurs parcourent les résultats ; les ingénieurs parcourent le raisonnement. Les deux veulent des résultats quantifiés.
4. Préparez-vous pour trois pistes d'entretien distinctes. Codage (LeetCode moyen, principalement tableaux et hashmaps pour les rôles IA — vous n'avez pas besoin de programmation dynamique difficile), conception du système ML (comment construiriez-vous les recommandations YouTube ? comment détecteriez-vous la dérive en production ?), et ML appliqué (déboguez ce notebook, expliquez cet article, critiquez cette méthodologie d'évaluation). Répartissez le temps de pratique sur les trois. La plupart des candidats sur-préparent le LeetCode et sous-préparent la conception du système — exactement inversé par rapport à où les offres sont gagnées.
5. Négociez les routes d'entrée, pas seulement les offres. La conversion de contrat à FTE chez les startups natives IA est de plus en plus courant. Accepter un contrat payant de trois mois avec une route FTE déclarée peut contourner entièrement l'entonnoir d'embauche standard. Les rôles juniors chez les consultances (Slalom, Thoughtworks, BCG GAMMA) donnent 18 mois d'exposition à des projets IA variés à une comp de démarrage inférieure — pesez explicitement la vélocité d'apprentissage par rapport à la comp. Le rôle qui maximise votre trajectoire de compétences au mois 24 est souvent pas l'offre première année la plus élevée.
6. Participez à deux communautés, pas sept. Choisissez un Slack ou Discord (MLOps Community, Latent Space, Hugging Face Discord) et une communauté en personne (rencontre IA locale, une conférence par an). La profondeur de présence dans deux communautés bat la lurking dans sept. Les gens recommandent les candidats qu'ils reconnaissent. La reconnaissance nécessite une présence cohérente et contributive — répondre aux questions, partager les mises à jour de projet, assister aux heures de bureau.
7. Suivez votre recherche d'emploi comme un pipeline. Sensibilisation envoyée, réponses reçues, appels programmés, take-homes reçus, on-sites, offres. Examinez hebdomadairement. Si le taux de réponse est inférieur à 8%, votre CV ou votre message de sensibilisation a besoin d'une révision avant que plus de volume aide. Si la conversion de take-home en on-site est faible, votre documentation de code est le goulot. Si la conversion d'on-site en offre est faible, votre préparation aux entretiens a besoin de travail. Déboguez l'entonnoir où il fuit — même discipline d'évaluation que celle que vous avez appliquée à vos modèles.
Même les candidats solides avec des portfolios expédiés ont généralement besoin de 3-5 mois de recherche active pour débarquer leur premier rôle d'ingénieur IA en 2026. La barre est élevée parce que le plafond est élevé. Les candidats qui débarquent les offres sont ceux qui traitent la recherche elle-même comme un système à déboguer — pas une loterie à entrer. Pour plus de cadres sur la construction de systèmes de carrière et de produit durables, aymartech publie des livrets adjacents qui valent la peine d'être mis en signet.
Questions courantes sur la façon de devenir ingénieur IA en 2026
Ai-je besoin d'un diplôme en informatique pour devenir ingénieur IA ?
Non — mais vous devez compenser ce que le diplôme signale. Un diplôme en informatique donne aux recruteurs un proxy de compétence rapide : structures de données, pensée système, intuition algorithmique. Sans cela, votre portfolio porte la charge de signalisation complète. Les ingénieurs autodidactes qui débarquent les rôles ont généralement une forte contribution open-source montrant la tolérance d'examen de code, un projet de bout en bout déployé avec une URL fonctionnelle, et des connaissances système démontrable (Docker, réseautage de base, SQL). Selon l'analyse CMU SEI, l'écart n'est presque jamais les identifiants — c'est la rigueur d'évaluation et la discipline de production. La route non-informatique ajoute environ 4-6 mois de délai par rapport à un diplômé en informatique faisant la même transition. Ce n'est pas fermé. C'est plus long, et la barre pour la qualité du portfolio est plus élevée.
Quelle est la différence réelle entre un data scientist et un ingénieur IA ?
Les data scientists répondent aux questions commerciales avec des modèles statistiques — lourd sur l'expérimentation, les présentations et la communication aux parties prenantes. Les ingénieurs IA expédient les systèmes — lourd sur le code en production, le déploiement et la surveillance. Les data scientists travaillent généralement dans les notebooks Jupyter ; les ingénieurs IA travaillent dans les IDE avec du code en production versionnés. La rémunération diverge en conséquence : les données d'industrie de formation mettent les gammes de salaire d'ingénieur IA à 130 K$-250 K$+ par rapport à 96 K$-150 K$ pour les data scientists aux États-Unis. Les rôles chevauchent de plus en plus dans les petites startups mais se séparent fortement dans les entreprises au-delà de 200 employés. Si vous aimez expédier du code plus que présenter les conclusions, ciblez ingénieur IA.
Devrais-je poursuivre une maîtrise ou l'auto-étude ?
L'auto-étude fonctionne pour la plupart des routes dans l'ingénierie IA et économise environ 40 K$-120 K$ en frais de scolarité. Un Master vaut la peine dans trois cas spécifiques : vous avez besoin d'un visa de travail aux États-Unis et le diplôme est votre chemin d'immigration ; vous ciblez des rôles de recherche dans des laboratoires industriels (DeepMind, Anthropic, FAIR) où les identifiants ont toujours du poids ; ou vous faites la transition à partir d'un domaine sans antécédents quantitatifs sur papier. Autrement, le coût d'opportunité de 18-24 mois d'une Master dépasse généralement le signal d'identifiant — surtout comparé à un portfolio solide construit dans le même laps de temps sans fardeau de frais de scolarité. L'exception qui vaut la peine d'être considérée : des programmes en ligne à temps partiel comme Georgia Tech OMSCS, qui coûtent moins de 10 K$ et ne vous sortent pas du marché du travail.
Comment la réglementation (Loi sur l'IA de l'UE, NIST AI RMF) affecte-t-elle l'embauche d'ingénieur au niveau d'entrée ?
Elle élargit l'embauche, ne la contracte pas. Les exigences réglementaires créent une demande pour les ingénieurs qui peuvent construire des pistes d'audit, documenter la provenance des données d'entraînement et implémenter des seuils de test de biais. Les candidats qui peuvent parler couramment des exigences de conformité — même au niveau junior — se différencient fortement dans les industries réglementées comme la finance, la santé et le secteur public. Lire le NIST AI RMF une fois avant les entretiens vous met devant la majorité des candidats au niveau d'entrée qui traitent la conformité comme le problème de quelqu'un d'autre. En pratique, les candidats qui jumelent la compétence de modélisation avec la littératie réglementaire commandent une prime dans la santé et fintech spécifiquement — ces équipes ne peuvent pas expédier sans cette combinaison, et l'offre est mince.