
Como se tornar um engenheiro de IA em 2026: habilidades, roteiro e ferramentas
Três Funções de Engenheiro de IA que Pagam Seis Dígitos — E Qual Combina com Seu Histórico

Você está lendo isto porque já fez as contas dos salários de engenheiro de IA — $130K a $250K+ nos EUA conforme dados de compensação da indústria de treinamento da Dataquest — e quer saber o que realmente é necessário para chegar lá. O Bureau de Estatísticas do Trabalho dos EUA projeta crescimento de 35% para cientistas de pesquisa em computação e informação (a categoria que inclui funções de IA) de 2022 a 2032, muito acima dos 4% de média para todas as ocupações, conforme o BLS. A oportunidade é real. Assim como a questão de como ser um engenheiro de IA quando metade da internet está vendendo um bootcamp.
Aqui é onde fica desconfortável. Uma análise do IEEE Spectrum de listagens de empregos de 2025 descobriu que 68% das postagens etiquetadas como "Engenheiro de IA" realmente descrevem engenharia de software avançada com trabalho de IA mínimo, conforme IEEE Spectrum. Tradução: mais da metade das listagens para as quais você está se candidatando não querem o que o título diz que querem. A inflação de títulos é o segredo menos guardado do mercado.
Este artigo não finge que você será contratado em 90 dias. Ele oferece a sequência real — qual especialização escolher, quais fundações importam (e quais pular), como construir um portfólio que sobrevive ao clique no GitHub de um engenheiro sênior, e como converter habilidades em ofertas. Sem links de afiliados de bootcamp. Sem hype.
Índice
- Três Funções de Engenheiro de IA que Pagam Seis Dígitos — E Qual Combina com Seu Histórico
- Habilidades Fundamentais que Realmente o Contratam (E a Teoria que Você Pode Pular)
- O Roteiro de 12 Meses para Engenheiro de IA: Uma Sequência Trimestral
- Projetos de Portfólio que Realmente Geram Callbacks de Recrutadores
- O Toolkit de Engenharia de IA: O Que Realmente é Usado em Produção vs. Enchimento de Currículo
- Converta Habilidades em Ofertas: O Playbook de Networking e Entrevista
- Perguntas Comuns Sobre Tornar-se um Engenheiro de IA em 2026
Três Funções de Engenheiro de IA que Pagam Seis Dígitos — E Qual Combina com Seu Histórico
"Engenheiro de IA" é agora um termo guarda-chuva. Gerentes de contratação na Anthropic, Stripe e Mayo Clinic procuram por três perfis distintos, e as habilidades necessárias divergem acentuadamente após o terceiro mês de aprendizado. Escolha um antes de escolher um livro. Escolher tarde significa re-aprender uma pilha de estrutura diferente no mês sete — essa é a razão mais comum pela qual os mudadores de carreira se queimam.
Engenheiro de ML. Treina modelos, projeta experimentos, dimensiona pipelines de treinamento. Matemática pesada: álgebra linear, probabilidade, teoria da otimização. Este é o caminho em empresas com ativos de dados proprietários — recomendações Netflix, ranking Spotify, fraude Stripe. Você passará mais tempo na engenharia de características e rigor de avaliação do que em construir sistemas voltados para o usuário. Bom ajuste para históricos em CS, estatística, física ou matemática aplicada.
Engenheiro de LLM/GenAI. Constrói aplicações sobre modelos base. Pesado em engenharia de prompts, geração aumentada por recuperação (RAG), arneses de avaliação e fine-tuning eficiente em parâmetros com LoRA ou QLoRA. Comum em startups nativas de IA e equipes corporativas lançando cópias internas. A especialização de crescimento mais rápido em contratação de 2025. Bom ajuste para engenheiros de produto e engenheiros full-stack — você já sabe como lançar; está aprendendo a camada de modelagem.
Engenheiro de Sistemas de IA / MLOps. Proprietário de implantação, monitoramento e confiabilidade de infraestrutura. Pesado em Docker, Kubernetes, model serving (Triton, BentoML) e ferramentas de observabilidade (Weights & Biases, Arize). Comum em indústrias reguladas — finanças, saúde, setor público — onde a estabilidade de produção importa mais do que modelagem inovadora. Bom ajuste para engenheiros backend, DevOps e engenheiros de confiabilidade de site adicionando o ciclo de vida do modelo ao seu toolkit existente.
| Função | Profundidade de Matemática | Ferramentas Primárias | Faixa de Salário Típica (EUA) | Melhor Histórico de Entrada |
|---|---|---|---|---|
| Engenheiro de ML | Profunda | PyTorch, scikit-learn, Spark | $128K–$220K+ | CS, estatística, física |
| Engenheiro de LLM/GenAI | Moderada | Hugging Face, LangChain, LoRA, vector DBs | $130K–$250K+ | Engenharia de software |
| Sistemas de IA / MLOps | Leve (nível de sistema) | Docker, K8s, Triton, MLflow, W&B | $135K–$230K+ | Backend, DevOps, SRE |
Faixas salariais obtidas de dados de compensação da indústria de treinamento Dataquest — verifique contra Levels.fyi para intervalos de oferta específicos.
O mercado não recompensa generalistas ainda. Ele recompensa especialistas que podem lançar um sistema funcionando em seu segmento dentro de noventa dias de contratação.
Conforme relatado pelo Relatório de Índice de IA 2025 da Stanford HAI, 56% das empresas agora têm funções dedicadas de engenharia de IA, acima de 32% em 2023. A especialização em LLM/GenAI está crescendo mais rápido em contratação corporativa, mas a trilha MLOps tem a taxa de conversão de oferta mais alta porque o fornecimento é genuinamente restringido — engenheiros backend que obtiveram profundidade em MLOps são mais raros do que tramadores de LLM recém-treinados.
Verifique isto com a descoberta do IEEE sobre inflação de função. O único filtro mais eficaz que você pode aplicar à sua busca de emprego não é título — é corresponder sua especialização ao trabalho real descrito em uma postagem. Leia a seção de responsabilidades. Se uma função "Engenheiro de IA Sênior" listar "projetar APIs RESTful, otimizar consultas PostgreSQL e integrar com webhooks Stripe", essa é uma função backend com palavras-chave de IA. Passe adiante.
Habilidades Fundamentais que Realmente o Contratam (E a Teoria que Você Pode Pular)
A maioria dos roteiros de engenheiro de IA começam com seis meses de cálculo multivariável e teoria da medida. Você não precisa disso para ser contratado. Você precisa de uma compreensão funcional de cinco domínios — o suficiente para ler um artigo, depurar um modelo e explicar uma troca em uma entrevista. O Dr. Michael Chen do Institute of Software Engineering da CMU analisou 500 repos GitHub de engenheiros de IA autodidata e descobriu que apenas 12% implementaram estruturas de avaliação apropriadas, conforme CMU SEI. A lacuna que mata ofertas raramente é "mais matemática". É disciplina de produção.

Álgebra linear e cálculo — apenas o subconjunto de trabalho. Você precisa de: operações matriciais (multiplicação, inversa, transposta), autovalores e autovetores em nível intuitivo, gradientes e a regra da cadeia, distribuições de probabilidade básicas. Você pode pular: análise real, teoria da medida, provas formais. A série de vídeo YouTube "Essence of Linear Algebra" de 3Blue1Brown cobre aproximadamente 80% do conhecimento de trabalho em cerca de quatro horas. Se você puder derivar retropropagação em papel para uma rede de duas camadas, você tem o suficiente.
Python — o ecossistema de IA, não apenas a linguagem. Além de sintaxe: transmissão de array NumPy, operações de agrupamento, fusão e séries temporais de Pandas, tensores PyTorch e autograd, async/await para trabalho de API e empacotamento moderno com Poetry ou uv. Gerentes de contratação testam compreensões de lista, decoradores e gerenciadores de contexto em telas técnicas — não quebra-cabeças algorítmicos que você veria em uma entrevista FAANG. Fique fluente em Python idiomático antes de tocar um modelo.
Estatística e design de avaliação. Testes de hipótese, intervalos de confiança, design de teste A/B com cálculo de tamanho de amostra e correção de comparações múltiplas, e métricas de avaliação de modelo que vão além de acurácia: tradeoffs de precisão/recall, curvas ROC/AUC, calibração, BLEU e ROUGE para texto e avaliação específica de LLM (LLM-as-judge, conjuntos dourados, recall@k de recuperação). Conforme o Framework de Gerenciamento de Riscos de IA do NIST, os sistemas de produção devem testar em um mínimo um conjunto de avaliação selecionado com limites de viés e desempenho documentados. Se seu projeto de portfólio não tiver um relatório de avaliação, ele se lê como incompleto.
SQL e data wrangling — inegociável, mesmo para engenheiros de LLM. Cada sistema de IA de produção extrai de um banco de dados. Você precisa de: joins (inner, left, funções de janela), CTEs, otimização de consulta (índices, planos EXPLAIN) e pelo menos um banco de dados vetor — pgvector, Pinecone ou Weaviate — para trabalho RAG. Pule Hadoop completamente. Aprenda Spark apenas se suas postagens de emprego alvo mencionarem explicitamente. DuckDB é a joia subestimada que vale dois fins de semana de estudo.
Git, Docker e uma plataforma em nuvem. Estratégias de ramificação (baseada em tronco ou GitHub Flow), escrevendo Dockerfiles que não produzem inchaço de imagem de 8GB e implantando em AWS, GCP ou Azure. Você não precisa de Kubernetes para seu primeiro cargo. A maioria das equipes de engenharia de IA tratam K8s como território de equipe de plataforma, não responsabilidade do engenheiro de modelagem. Listar K8s em seu currículo sem um projeto real usando-o se lê como enchimento de currículo para entrevistadores experientes.
O objetivo não é uma quantidade de teoria de grau em CS. É fluência suficiente para lançar. Se você puder treinar um modelo, avaliá-lo em um conjunto retido, implantá-lo atrás de um ponto de extremidade FastAPI e defender sua metodologia de avaliação em uma entrevista — você limpou o bar para a vasta maioria de funções de engenheiro de IA de nível de entrada.
O Roteiro de 12 Meses para Engenheiro de IA: Uma Sequência Trimestral
Provedores de treinamento como Dataquest sugerem que um engenheiro de software pode fazer a transição em 3-5 meses — considere isso como estimativa de fornecedor, não consenso da indústria. A análise CMU SEI sugere que esse cronograma é irrealista para trabalho de qualidade de produção para alguém começando do zero. O cronograma realista: aproximadamente 12 meses em tempo parcial (15-20 horas por semana) para um histórico não-CS para alcançar competência contratável, cerca de 6-8 meses para um engenheiro de software trabalhando adicionando especialização em IA. Este roteiro assume o caminho mais longo. Comprima por sua conta e risco.

Trimestre 1 (Meses 1–3): Python Fundamental + Atualização de Matemática + Primeiro Notebook Lançado
Foco diário: 60% de prática com Python, Pandas e NumPy, 30% de álgebra linear via 3Blue1Brown e Khan Academy, 10% lendo postagens de empregos de engenharia de IA para internalizar o que "pronto" parece no seu mercado alvo. Ler postagens não é procrastinação — é pesquisa de mercado.
Recursos gratuitos recomendados: Curso Practical Deep Learning Course 1 da fast.ai, trilha "Intro to Machine Learning" do Kaggle e o Curso NLP da Hugging Face. Os três são genuinamente gratuitos e construídos por profissionais que lançam.
Marco do portfólio: Uma entrada de competição Kaggle com um notebook público documentando suas decisões de engenharia de características e razão de escolha do modelo. Critério de saída: você pode carregar um CSV, treinar um modelo scikit-learn de linha de base, avaliá-lo em um conjunto retido e explicar em um parágrafo por que escolheu sua métrica de avaliação em vez das alternativas.
Trimestre 2 (Meses 4–6): Fundamentos de ML + Primeiro Projeto de Ponta a Ponta
Foco diário: imersão profunda em scikit-learn, rigor de avaliação de modelo, introdução ao PyTorch. Tópicos que importam: regularização, validação cruzada, ajuste de hiperparâmetro, por que seu conjunto de teste vazou (vai vazar), e calibração. O modo de falha único mais comum para engenheiros autodidata: desempenho de conjunto de treinamento que não sobrevive ao contato com dados de retenção reais.
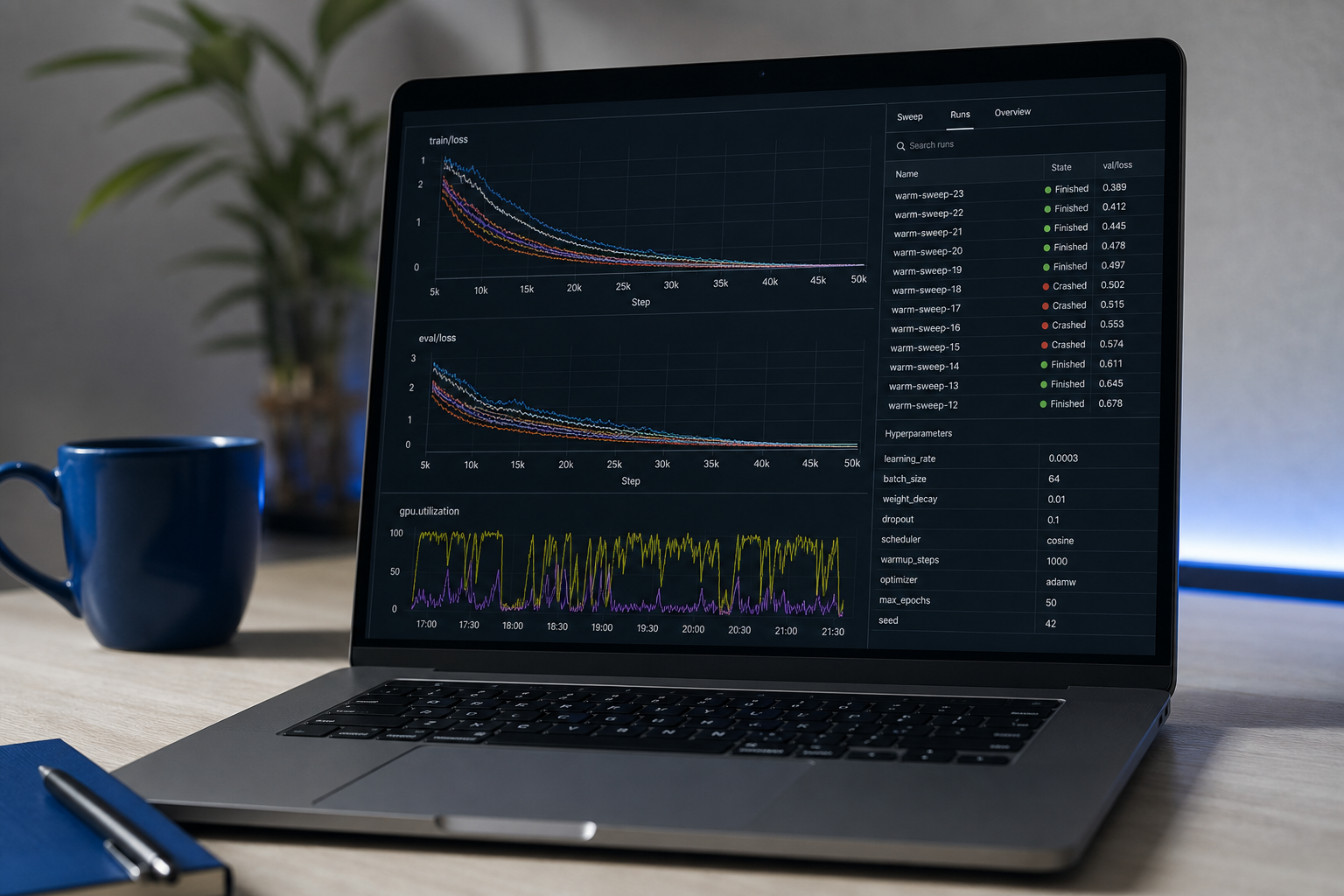
Marco do portfólio #1: Um projeto de ponta a ponta com dados limpos, um modelo treinado, um relatório de avaliação e um ponto de extremidade de inferência FastAPI implantado em Railway, Fly.io ou Hugging Face Spaces. Critério de saída: uma URL de demonstração funcionando que alguém pode acessar, com um README explicando metodologia e limitações conhecidas. A URL implantada é inegociável — um notebook que vive em Colab sinaliza trabalho incompleto.
Trimestre 3 (Meses 7–9): Deep Learning + Escolha de Especialização
Aqui é onde você se compromete com uma das três especialidades de antes. Pare de se cobrir.
Trilha Engenheiro de ML: Fundamentos PyTorch, loops de treinamento que você escreveu você mesmo (não Lightning), noções básicas de treinamento distribuído (DDP), uma tentativa de medalha Kaggle com experimentação documentada.
Trilha Engenheiro de LLM: Transformers Hugging Face, fine-tuning LoRA e QLoRA em um conjunto de dados de domínio, um pipeline RAG completo com um banco de dados vetor e um arnês de avaliação de LLM usando Promptfoo ou Ragas.
Trilha MLOps: Docker para fluxos de trabalho ML, registros de modelo via MLflow, monitoramento de desvio com Evidently ou Arize e pipelines CI/CD que retreinam modelos em um cronograma.
Marco do portfólio #2: Um projeto específico de especialização. Para LLM: um modelo de domínio ajustado com um conjunto de avaliação documentado cobrindo no mínimo 200 prompts. Para MLOps: um modelo implantado com painéis de monitoramento e um gatilho de retreinamento automatizado.
Aprender uma estrutura profundamente torna a segunda óbvia. Aprender duas estruturas superficialmente torna você útil para nenhuma.
Trimestre 4 (Meses 10–12): Open Source, Networking, Preparação de Entrevista
Foco diário: uma contribuição de código aberto (Hugging Face, LangChain, scikit-learn — comece com PRs de documentação para aprender o fluxo de contribuição), duas mensagens de contato a frio por dia e uma sessão de preparação de entrevista combinando um médio LeetCode com prática de design de sistema de ML.
Marco do portfólio: um PR aceito para um repositório reconhecido, mais uma redação técnica de menos de 1.500 palavras em seu site pessoal ou Substack sobre uma troca que você enfrentou em seus projetos de portfólio. Estas redações técnicas que constroem visibilidade de pesquisa são o artefato que converte contato de recrutador a frio em respostas calorosas.
Critério de saída: três ou mais conversas de recrutador ativas, uma referência de contrato pago ou mantenedor de código aberto e um currículo polido alinhado à sua especialização escolhida.
Uma nota sobre adaptabilidade como meta-habilidade: o ecossistema LLM mudou três vezes em 2024 — RAG, depois agentes, depois uso de ferramentas. O roteiro acima o ensina a camada durável (matemática, avaliação, implantação) para que você possa absorver a mudança do próximo ano sem recomeçar do zero. Os candidatos que prosperam a longo prazo não são os que memorizaram a pilha deste ano. Eles são os que construíram o julgamento para avaliar a próxima.
Projetos de Portfólio que Realmente Geram Callbacks de Recrutadores
Um portfólio é um filtro de contratação, não uma saída criativa. Recrutadores gastam uma média de seis segundos em um currículo e aproximadamente 90 segundos clicando em um GitHub. Seu trabalho: fazer os primeiros três projetos que eles veem sinalizar prontidão de produção, não entusiasmo amador. Repositórios fixados importam mais do que contagem total de repositórios.
| Tipo de Projeto | O Que Demonstra | Tempo de Construção | Sinal do Recrutador |
|---|---|---|---|
| Competição Kaggle (top 25%) | Engenharia de características, disciplina de avaliação | 3-5 semanas | Reprodutibilidade |
| Sistema ML de ponta a ponta | Pensamento de produção, implantação | 4-6 semanas | Pode lançar, não apenas treinar |
| LLM ajustado + pacote de avaliação | LoRA/QLoRA, design de avaliação, fluência GenAI | 3-4 semanas | Ecossistema atual |
| PR de código aberto (aceito) | Tolerância a revisão de código | 2-8 semanas | Qualidade validada por pares |
| Reimplementação de artigo | Compreensão de método | 6-10 semanas | Profundidade acadêmica (mista) |
Amplitude bate profundidade para candidatos de nível de entrada. Três projetos de complexidade média em domínios diferentes — um ML tabular, um LLM, um focado em implantação — sinaliza alcance. Uma reimplementação brilhante de artigo de pesquisa sinaliza "acadêmico, pode não lançar". Gerentes de contratação em empresas lideradas por produtos leem o segundo perfil e passam. A exceção: se você está visando laboratórios de pesquisa (Anthropic, DeepMind, FAIR), inverta isto — profundidade vence.
A rubrica de avaliação é o projeto. Conforme as diretrizes do NIST AI RMF citadas antes, os sistemas de IA de produção exigem limites de avaliação documentados. Um projeto de portfólio sem um relatório de avaliação — curvas de precisão/recall, análise de justiça em subgrupos, análise de erros em exemplos mal classificados — se lê como incompleto para engenheiros sênior. O notebook é a parte fácil. O rigor de avaliação é o diferenciador.
Implantação importa mais do que novidade de modelo. Recrutadores cada vez mais priorizam candidatos que podem mostrar um sistema implantado em relação àqueles com classificações Kaggle mais altas mas sem código lançado. Um modelo modesto atrás de uma API funcionando bate um notebook sofisticado que nunca saiu de Colab. A razão é desagradável, mas prática: nos seus primeiros 90 dias no cargo, você lançará um sistema v1, não inventará uma nova arquitetura. Gerentes de contratação querem evidência do primeiro.
Documente as trocas que você rejeitou. Um README de 500 palavras explicando por que você escolheu Random Forest em vez de XGBoost, por que usou similaridade de cosseno em vez de produto de ponto na sua recuperação RAG, o que faria diferente com mais computação — este é o artefato que vence em entrevistas. Demonstra o julgamento que os gerentes de contratação não podem testar de uma revisão de código sozinha. A maioria dos candidatos pula isto porque escrever é mais difícil que codificar. Incline-se para a assimetria.
O Toolkit de Engenharia de IA: O Que Realmente é Usado em Produção vs. Enchimento de Currículo
Esta seção é opinativa por design. O cenário de ferramentas de IA é barulhento e a maioria das listas "imprescindíveis" do LinkedIn são escritas por pessoas vendendo cursos sobre essas ferramentas exatas. O que se segue é o que equipes de produção realmente executam em 2026.
Estruturas de ML principais — PyTorch vence para novos aprendizes. PyTorch domina pesquisa nova e a maioria das ferramentas de LLM (Hugging Face, vLLM, Axolotl) é primeiro PyTorch. TensorFlow permanece dominante dentro do Google e em alguns ambientes de produção corporativa construídos antes de 2022. Aprenda PyTorch primeiro. Se um trabalho alvo exigir TensorFlow, você pode aprendê-lo em cerca de três semanas assim que entender o tensor subjacente e as primitivas autograd.
Ecossistema de LLM — Hugging Face é o piso, LangChain é opcional. Hugging Face Transformers, Datasets e o Hub são inegociáveis em 2026. LangChain é amplamente utilizado mas amplamente criticado por sobre-abstração — muitas equipes de produção passaram para chamadas de API diretas com orquestração personalizada após atingir as abstrações com vazamento de LangChain em postmortems de incidente. Aprenda LangChain o suficiente para ler o código de outras pessoas; não ancorize sua pilha inteira nele. LlamaIndex é a melhor escolha para aplicações pesadas em RAG. DSPy vale a pena observar, mas ainda não é um requisito de contratação.
As ferramentas de enchimento de currículo o colocam além do filtro de palavra-chave e o esmagram na entrevista técnica. Escolha a pilha que você pode defender sob questionamento.
Ferramentas de avaliação — o diferenciador que a maioria dos candidatos pula. Esta é a lacuna que separa engenheiros sênior de engenheiros juniores em entrevistas e a área de habilidade mais pouco investida em roteiros autodidata. Ferramentas para aprender: Promptfoo ou Ragas para avaliação de LLM, Evidently AI para detecção de desvio tabular, Weights & Biases para rastreamento de experimento. Conforme análise de fluxo de trabalho de McKay Johns, analista independente, os sistemas de IA de produção exigem protocolos de avaliação testando um mínimo de 500 entradas diversas com tolerâncias de erro documentadas. Se você puder falar fluentemente sobre sua metodologia de avaliação, você já se separou da maioria dos candidatos.
Pilha de implantação — comece pequeno, K8s não é o problema do seu primeiro contratado. Docker é essencial. FastAPI para servir. Modal, Replicate ou Hugging Face Inference Endpoints para hospedagem de modelo sem dor de infraestrutura. Kubernetes é genuinamente necessário em escala, mas a maioria das equipes de engenharia de IA trata K8s como território de equipe de plataforma. Listar K8s em um currículo junior sem um projeto real que o usou se lê como enchimento. Sinal melhor: um Dockerfile que produz uma imagem de menos de 2GB com cache adequado de camada.
Dados e orquestração — escolhas pragmáticas vencem. Pandas para conjuntos de dados de menos de 100GB. DuckDB para consultas analíticas em arquivos Parquet (negligenciado criminosamente — é a hora mais eficiente que você pode investir). Polars quando Pandas fica lento. Apache Spark apenas se seu empregador alvo o executa explicitamente. Para orquestração, Airflow é incumbente; Prefect e Dagster estão ganhando; escolha baseado na frequência de postagem de emprego no seu mercado alvo. Para bancos de dados de vetor: pgvector se você já executa Postgres, Pinecone se precisar de um serviço gerenciado hoje, Weaviate se precisar de código aberto com busca híbrida.
Ao avaliar qualquer ferramenta nova, faça três perguntas: É usada por pelo menos três empresas para as quais você aceitaria uma oferta? Resolve um problema que você realmente acertou ou você está aprendendo isto preventivamente? Ainda será mantida em 18 meses? A maioria das "ferramentas de IA imprescindíveis" no LinkedIn falha em pelo menos dois desses verifica. O ecossistema que muda rapidamente recompensa profundidade em algumas camadas estáveis, não amplitude entre o ciclo de hype. É assim que avaliamos durabilidade de ferramenta de IA em domínios adjacentes também — mesmo princípio, mesmo filtro.
Converta Habilidades em Ofertas: O Playbook de Networking e Entrevista
A maioria dos guias "como ser um engenheiro de IA" para aqui em "construa habilidades". Essa é a metade fácil. A metade mais difícil — e a que decide se você está trabalhando em IA em mês 14 ou mês 30 — é networking e narrativa de entrevista. Contratação é um problema de distribuição, não uma meritocracia. Trate dessa forma.

1. Construa em público, não em sigilo. Poste uma redação técnica por mês em um site pessoal, dev.to ou Substack. Compartilhe no LinkedIn três vezes por semana sobre o que você está construindo — não levantamentos genéricos de IA, mas lições específicas dos seus projetos. Conforme a análise do IEEE Spectrum citada antes, o mercado de talentos de engenheiro de IA é barulhento; visibilidade é um filtro que recrutadores usam antes de abrir seu currículo. Se você não tiver um site ainda, projete um site pessoal usando um fluxo de trabalho de IA e pule o desvio de duas semanas do WordPress.
2. Contato a frio 5 engenheiros de IA por semana em empresas alvo. Não recrutadores — engenheiros. Faça uma pergunta específica sobre sua pilha de tecnologia ou um artigo de blog recente que escreveram. A taxa de conversão para um café virtual é tipicamente cerca de 10-15% quando a mensagem é genuinamente específica. Ao longo de 12 semanas, isto gera aproximadamente 6-9 entrevistas informacionais — historicamente o maior conversor de topo de funil para ofertas de engenharia. O contato genérico converte em menos de 2%. A diferença é ler seu trabalho antes de você enviar uma mensagem.
3. Estruture projetos de portfólio como problemas resolvidos, não ferramentas usadas. "Construiu um modelo de detecção de fraude" perde para "Reduziu taxa de falso positivo de 12% para 4% em um conjunto de dados de 200K transações ao mudar de regressão logística para boosting de gradiente e adicionar três características engineered." Números e decisões, não pilhas de tecnologia. Recrutadores escannem resultados; engenheiros escannem raciocínio. Ambos querem resultados quantificados.
4. Prepare-se para três trilhas de entrevista distintas. Codificação (LeetCode médio, principalmente arrays e hashmaps para funções de IA — você não precisa de programação dinâmica difícil), design de sistema de ML (como você construiria recomendações do YouTube? como detectaria desvio em produção?) e ML aplicado (depure este notebook, explique este artigo, critique esta metodologia de avaliação). Aloque tempo de prática em todos os três. A maioria dos candidatos sobre-prepara em LeetCode e sub-prepara em design de sistema — exatamente invertido de onde as ofertas vencem.
5. Negocie rotas de entrada, não apenas ofertas. Conversão de contrato para FTE em startups nativos de IA está se tornando cada vez mais comum. Aceitar um contrato pago de três meses com uma conversão FTE indicada pode contornar o funil de contratação padrão inteiramente. Funções juniores em consultórios (Slalom, Thoughtworks, BCG GAMMA) dão exposição de 18 meses a projetos de IA variados com comp de partida menor — pese velocidade de aprendizado versus comp explicitamente. O cargo que maximiza sua trajetória de habilidade no mês 24 geralmente não é a oferta mais alta de primeiro ano.
6. Participe de duas comunidades, não sete. Escolha um Slack ou Discord (MLOps Community, Latent Space, Hugging Face Discord) e uma comunidade presencial (encontro de IA local, uma conferência por ano). Profundidade de presença em duas comunidades bate estar em lurking em sete. As pessoas recomendam candidatos que elas reconhecem. Reconhecimento requer presença consistente e contributiva — responder perguntas, compartilhar atualizações de projeto, participar de horários de escritório.
7. Acompanhe sua busca de emprego como um pipeline. Contato enviado, respostas recebidas, chamadas agendadas, trabalhos de casa recebidos, onsites, ofertas. Revise semanalmente. Se a taxa de resposta está abaixo de 8%, seu currículo ou mensagem de contato precisa de revisão antes de mais volume ajudar. Se a conversão de trabalho de casa para onsite é baixa, a documentação do seu código é o gargalo. Se onsite-para-oferta é baixa, sua preparação de entrevista precisa de trabalho. Depure o funil onde vaza — mesma disciplina de avaliação que você aplicou aos seus modelos.
Mesmo candidatos fortes com portfólios lançados precisam tipicamente de 3-5 meses de busca ativa para aterrissar seu primeiro cargo de engenheiro de IA em mercado de 2026. O bar é alto porque o teto é alto. Os candidatos que aterrisam ofertas são os que tratam a busca em si como um sistema para depurar — não uma loteria para entrar. Para mais estruturas em construir sistemas de carreira e produto duráveis, aymartech publica playbooks adjacentes que valem a pena marcar.
Perguntas Comuns Sobre Tornar-se um Engenheiro de IA em 2026
Preciso de um diploma em CS para ser um engenheiro de IA?
Não — mas você precisa compensar o que o diploma sinaliza. Um diploma em CS oferece aos recrutadores uma proxy rápida de competência: estruturas de dados, pensamento de sistemas, intuição algorítmica. Sem ele, seu portfólio carrega a carga de sinalização completa. Engenheiros autodidata que aterrisam funções tipicamente têm uma contribuição de código aberto forte mostrando tolerância a revisão de código, um projeto de ponta a ponta implantado com uma URL funcionando e conhecimento de sistemas demonstrável (Docker, rede básica, SQL). Conforme a análise CMU SEI, a lacuna raramente é credenciais — é rigor de avaliação e disciplina de produção. O caminho não-CS adiciona aproximadamente 4-6 meses de cronograma versus um graduado em CS fazendo a mesma transição. Não está fechado. É mais longo e o bar para qualidade de portfólio é mais alto.
Qual é a diferença real entre um cientista de dados e um engenheiro de IA?
Cientistas de dados respondem perguntas de negócios com modelos estatísticos — pesado em experimentação, apresentações e comunicação com stakeholders. Engenheiros de IA lançam sistemas — pesado em código de produção, implantação e monitoramento. Cientistas de dados tipicamente trabalham em notebooks Jupyter; engenheiros de IA trabalham em IDEs com código de produção versionado. A compensação diverge conforme: dados de indústria de treinamento colocam faixas salariais de engenheiro de IA em $130K-$250K+ versus $96K-$150K para cientistas de dados nos EUA. As funções se sobrepõem cada vez mais em startups pequenas, mas se separam agudamente em empresas passadas de 200 funcionários. Se você gosta mais de lançar código do que apresentar descobertas, direcione engenheiro de IA.
Devo buscar um diploma de mestrado ou auto-estudo?
Auto-estudo funciona para a maioria dos caminhos em engenharia de IA e economiza aproximadamente $40K-$120K em mensalidades. Um mestrado vale a pena em três casos específicos: você precisa de um visto de trabalho dos EUA e o diploma é sua via de imigração; você está visando funções de pesquisa em laboratórios industriais (DeepMind, Anthropic, FAIR) onde credenciais ainda carregam peso; ou você está fazendo transição de um campo sem histórico quantitativo em papel. Caso contrário, o custo de oportunidade de 18-24 meses de um mestrado geralmente supera o sinal de credencial — especialmente comparado com um portfólio forte construído no mesmo prazo sem fardo de mensalidade. A exceção que vale considerar: programas online em tempo parcial como Georgia Tech OMSCS, que custam menos de $10K e não o retiram do mercado de trabalho.
Como a regulação (EU AI Act, NIST AI RMF) afeta contratação de engenheiro de nível de entrada?
Ela expande contratação, não contrai. Requisitos regulatórios estão criando demanda por engenheiros que possam construir trilhas de auditoria, documentar proveniência de dados de treinamento e implementar limites de teste de viés. Candidatos que podem falar fluentemente sobre requisitos de conformidade — mesmo em nível junioral — se diferenciam fortemente em indústrias reguladas como finanças, saúde e setor público. Ler o NIST AI RMF uma vez antes de entrevistas o coloca à frente da maioria dos candidatos de nível de entrada que tratam conformidade como problema de alguém. Na prática, os candidatos que unem habilidade de modelagem com letramento regulatório comandam um prêmio em saúde e fintech especificamente — essas equipes não podem lançar sem essa combinação e o fornecimento é fino.