
How to Become an AI Engineer in 2026: Skills, Roadmap, and Tools
Three AI Engineer Roles That Pay Six Figures — And Which One Fits Your Background

You're reading this because you've already done the math on AI engineer salaries — $130K to $250K+ in the US per training-industry compensation data from Dataquest — and you want to know what it actually takes to get there. The U.S. Bureau of Labor Statistics projects 35% growth for computer and information research scientists (the category that includes AI roles) from 2022 to 2032, far above the 4% average for all occupations, according to the BLS. The opportunity is real. So is the question of how to be an AI engineer when half the internet is selling you a bootcamp.
Here's where it gets uncomfortable. An IEEE Spectrum analysis of 2025 job listings found that 68% of postings labeled "AI Engineer" actually describe advanced software engineering with minimal AI-specific work, per IEEE Spectrum. Translation: more than half the listings you're applying to don't want what the title says they want. Title inflation is the market's worst kept secret.
This piece doesn't pretend you'll be hired in 90 days. It gives you the actual sequence — which specialization to pick, what foundations matter (and which to skip), how to build a portfolio that survives a senior engineer's GitHub click-through, and how to convert skills into offers. No bootcamp affiliate links. No hype.
Table of Contents
- Three AI Engineer Roles That Pay Six Figures — And Which One Fits Your Background
- Foundation Skills That Actually Get You Hired (And the Theory You Can Skip)
- The 12-Month AI Engineer Roadmap: A Quarter-by-Quarter Sequence
- Portfolio Projects That Actually Get Recruiter Callbacks
- The AI Engineering Toolkit: What's Actually Used in Production vs. Resume-Padding
- Convert Skills Into Offers: The Networking and Interview Playbook
- Common Questions About Becoming an AI Engineer in 2026
Three AI Engineer Roles That Pay Six Figures — And Which One Fits Your Background
"AI engineer" is now an umbrella term. Hiring managers at Anthropic, Stripe, and Mayo Clinic are looking for three distinct profiles, and the skills required diverge sharply after month three of learning. Pick one before you pick a textbook. Picking late means re-learning a different framework stack at month seven — that's the most common reason career-changers burn out.
ML Engineer. Trains models, designs experiments, scales training pipelines. Heavy math: linear algebra, probability, optimization theory. This is the path at companies with proprietary data assets — Netflix recommendations, Spotify ranking, Stripe fraud. You'll spend more time on feature engineering and evaluation rigor than on building user-facing systems. Strong fit for backgrounds in CS, statistics, physics, or applied math.
LLM/GenAI Engineer. Builds applications on top of foundation models. Heavy on prompt engineering, retrieval-augmented generation (RAG), evaluation harnesses, and parameter-efficient fine-tuning with LoRA or QLoRA. Common at AI-native startups and enterprise teams shipping internal copilots. The fastest-growing specialization in 2025 hiring. Strong fit for product engineers and full-stack software engineers — you already know how to ship; you're learning the modeling layer.
AI Systems / MLOps Engineer. Owns deployment, monitoring, and infrastructure reliability. Heavy on Docker, Kubernetes, model serving (Triton, BentoML), and observability tools (Weights & Biases, Arize). Common at regulated industries — finance, healthcare, public sector — where production stability matters more than novel modeling. Strong fit for backend engineers, DevOps, and site reliability engineers adding the model lifecycle to their existing toolkit.
| Role | Math Depth | Primary Tools | Typical Salary Band (US) | Best Entry Background |
|---|---|---|---|---|
| ML Engineer | Deep | PyTorch, scikit-learn, Spark | $128K–$220K+ | CS, statistics, physics |
| LLM/GenAI Engineer | Moderate | Hugging Face, LangChain, LoRA, vector DBs | $130K–$250K+ | Software engineering |
| AI Systems / MLOps | Light (system-level) | Docker, K8s, Triton, MLflow, W&B | $135K–$230K+ | Backend, DevOps, SRE |
Salary bands sourced from Dataquest training-industry compensation data — verify against Levels.fyi for specific offer ranges.
The market doesn't reward generalists yet. It rewards specialists who can ship a working system in their lane within ninety days of hire.
Per Stanford HAI's 2025 AI Index Report, 56% of enterprises now have dedicated AI engineering roles, up from 32% in 2023. The LLM/GenAI specialization is growing fastest in enterprise hiring, but the MLOps track has the highest offer-conversion rate because supply is genuinely constrained — backend engineers who've earned MLOps depth are scarcer than freshly-trained LLM tinkerers.
Cross-reference this with the IEEE finding on role inflation. The single highest-leverage filter you can apply to your job search isn't title — it's matching your specialization to the actual work described in a posting. Read the responsibilities section. If a "Senior AI Engineer" role lists "design RESTful APIs, optimize PostgreSQL queries, and integrate with Stripe webhooks," that's a backend role with AI buzzwords. Move on.
Foundation Skills That Actually Get You Hired (And the Theory You Can Skip)
Most AI engineer roadmaps front-load six months of multivariable calculus and measure theory. You don't need that to get hired. You need a working understanding of five domains — enough to read a paper, debug a model, and explain a tradeoff in an interview. Dr. Michael Chen of CMU's Software Engineering Institute analyzed 500 self-taught AI engineer GitHub repos and found only 12% implemented proper evaluation frameworks, per CMU SEI. The gap that kills offers is rarely "more math." It's production discipline.

Linear algebra and calculus — only the working subset. You need: matrix operations (multiplication, inverse, transpose), eigenvalues and eigenvectors at an intuitive level, gradients and the chain rule, basic probability distributions. You can skip: real analysis, measure theory, formal proofs. The free 3Blue1Brown "Essence of Linear Algebra" YouTube series covers roughly 80% of the working knowledge in about four hours. If you can derive backpropagation on paper for a two-layer network, you have enough.
Python — the AI ecosystem, not just the language. Beyond syntax: NumPy array broadcasting, Pandas groupby, merge, and time series operations, PyTorch tensors and autograd, async/await for API work, and modern packaging with Poetry or uv. Hiring managers test list comprehensions, decorators, and context managers in technical screens — not algorithmic puzzles you'd see at a FAANG interview. Get fluent in idiomatic Python before you touch a model.
Statistics and evaluation design. Hypothesis testing, confidence intervals, A/B test design with sample size calculation and multiple-comparisons correction, and model evaluation metrics that go beyond accuracy: precision/recall tradeoffs, ROC/AUC curves, calibration, BLEU and ROUGE for text, and LLM-specific evaluation (LLM-as-judge, golden datasets, retrieval recall@k). Per the NIST AI Risk Management Framework, production systems should test on at minimum a curated evaluation set with documented bias and performance thresholds. If your portfolio project lacks an evaluation report, it reads as incomplete.
SQL and data wrangling — non-negotiable, even for LLM engineers. Every production AI system pulls from a database. You need: joins (inner, left, window functions), CTEs, query optimization (indexes, EXPLAIN plans), and at least one vector database — pgvector, Pinecone, or Weaviate — for RAG work. Skip Hadoop entirely. Learn Spark only if your target job postings explicitly mention it. DuckDB is the underrated gem worth two weekends of study.
Git, Docker, and one cloud platform. Branching strategies (trunk-based or GitHub Flow), writing Dockerfiles that don't produce 8GB image bloat, and deploying to AWS, GCP, or Azure. You don't need Kubernetes for your first role. Most AI engineering teams treat K8s as platform-team territory, not the modeling engineer's responsibility. Listing K8s on your resume without a real project using it reads as resume-padding to experienced interviewers.
The goal isn't a CS degree's worth of theory. It's enough fluency to ship. If you can train a model, evaluate it on a held-out set, deploy it behind a FastAPI endpoint, and defend your evaluation methodology in an interview — you've cleared the bar for the vast majority of entry-level AI engineer roles.
The 12-Month AI Engineer Roadmap: A Quarter-by-Quarter Sequence
Training providers like Dataquest suggest a software engineer can transition in 3-5 months — label that as vendor estimate, not industry consensus. The CMU SEI analysis suggests that timeline is unrealistic for production-quality work for someone starting from zero. The realistic timeline: roughly 12 months part-time (15-20 hours per week) for a non-CS background to reach hireable competency, about 6-8 months for a working software engineer adding AI specialization. This roadmap assumes the longer path. Compress at your own risk.

Quarter 1 (Months 1–3): Core Python + Math Refresh + First Shipped Notebook
Daily focus: 60% Python, Pandas, and NumPy practice, 30% linear algebra via 3Blue1Brown and Khan Academy, 10% reading AI engineering job postings to internalize what "ready" looks like in your target market. Reading postings is not procrastination — it's market research.
Recommended free resources: fast.ai Practical Deep Learning Course 1, Kaggle's "Intro to Machine Learning" track, and the Hugging Face NLP Course. All three are genuinely free and built by practitioners who ship.
Portfolio milestone: One Kaggle competition entry with a public notebook documenting your feature engineering decisions and model choice rationale. Exit criteria: you can load a CSV, train a baseline scikit-learn model, evaluate it on a held-out set, and explain in one paragraph why you chose your evaluation metric over the alternatives.
Quarter 2 (Months 4–6): ML Fundamentals + First End-to-End Project
Daily focus: scikit-learn deep dive, model evaluation rigor, intro to PyTorch. Topics that matter: regularization, cross-validation, hyperparameter tuning, why your test set leaked (it will), and calibration. The single most common failure mode for self-taught engineers: training set performance that doesn't survive contact with real holdout data.
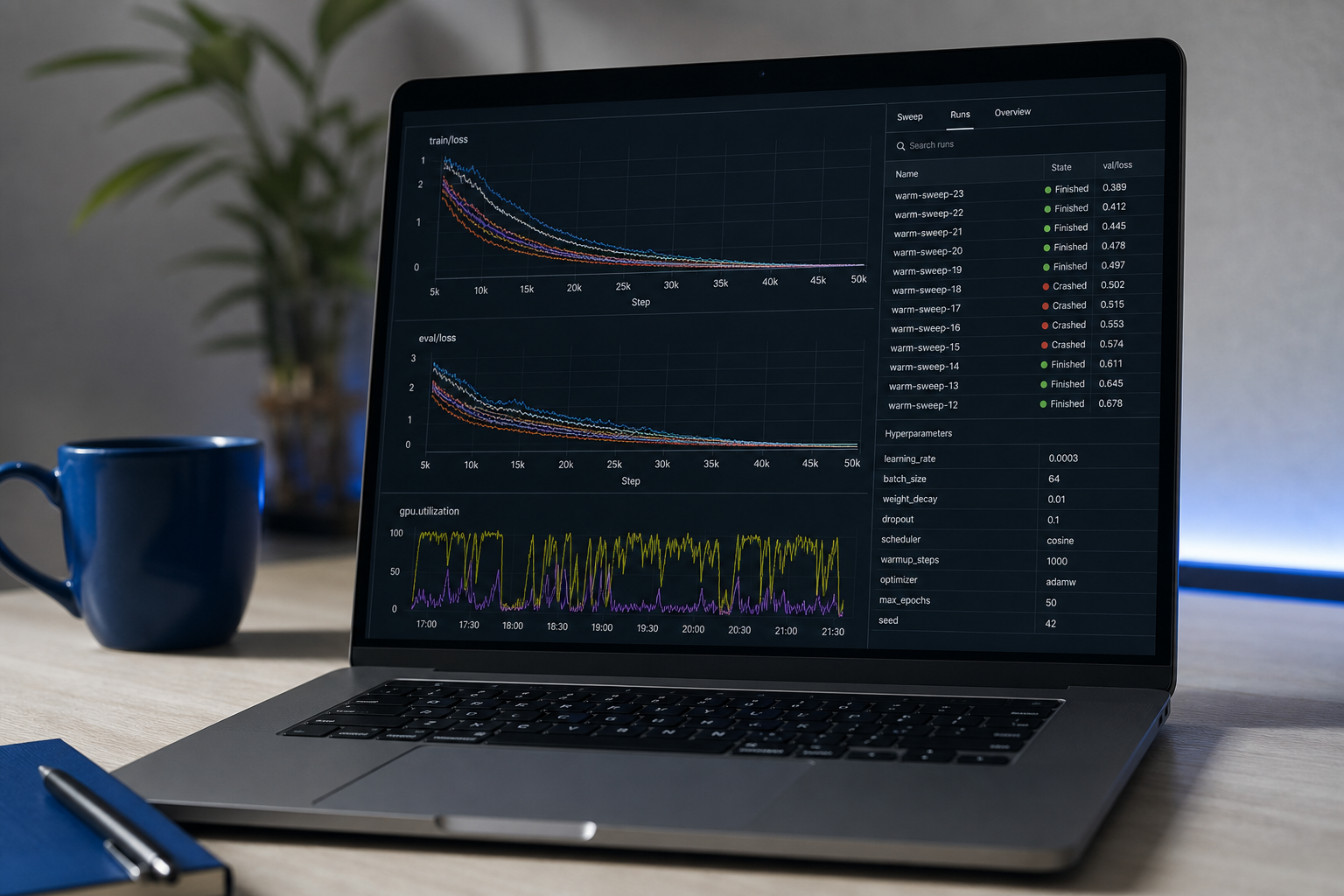
Portfolio milestone #1: An end-to-end project with cleaned data, a trained model, an evaluation report, and a FastAPI inference endpoint deployed on Railway, Fly.io, or Hugging Face Spaces. Exit criteria: a working demo URL someone can hit, with a README explaining methodology and known limitations. The deployed URL is non-negotiable — a notebook that lives in Colab signals incomplete work.
Quarter 3 (Months 7–9): Deep Learning + Specialization Choice
This is where you commit to one of the three specializations from earlier. Stop hedging.
ML Engineer path: PyTorch fundamentals, training loops you wrote yourself (not Lightning), distributed training basics (DDP), one Kaggle medal attempt with documented experimentation.
LLM Engineer path: Hugging Face Transformers, LoRA and QLoRA fine-tuning on a domain dataset, a complete RAG pipeline with a vector database, and an LLM evaluation harness using Promptfoo or Ragas.
MLOps path: Docker for ML workflows, model registries via MLflow, drift monitoring with Evidently or Arize, and CI/CD pipelines that retrain models on a schedule.
Portfolio milestone #2: A specialization-specific project. For LLM: a fine-tuned domain model with a documented evaluation suite covering at least 200 prompts. For MLOps: a deployed model with monitoring dashboards and an automated retraining trigger.
Learning one framework deeply makes the second one obvious. Learning two frameworks shallowly makes you useful for neither.
Quarter 4 (Months 10–12): Open Source, Networking, Interview Prep
Daily focus: one open-source contribution (Hugging Face, LangChain, scikit-learn — start with documentation PRs to learn the contribution flow), two cold outreach messages per day, and one interview prep session combining a LeetCode medium with ML system design practice.
Portfolio milestone: one accepted PR to a recognized repository, plus an under-1,500-word technical write-up on your personal site or Substack about a tradeoff you encountered in your portfolio projects. These technical write-ups that build search visibility are the artifact that converts cold recruiter outreach into warm replies.
Exit criteria: three or more active recruiter conversations, one paid contract or open-source maintainer reference, and a polished resume aligned to your chosen specialization.
A note on adaptability as the meta-skill: the LLM ecosystem shifted three times in 2024 — RAG, then agents, then tool use. The roadmap above teaches you the durable layer (math, evaluation, deployment) so you can absorb the next shift without restarting from scratch. The candidates who thrive long-term aren't the ones who memorized this year's stack. They're the ones who built the judgment to evaluate next year's.
Portfolio Projects That Actually Get Recruiter Callbacks
A portfolio is a hiring filter, not a creative outlet. Recruiters spend an average of six seconds on a resume and roughly 90 seconds clicking through a GitHub. Your job: make the first three projects they see signal production-readiness, not hobbyist enthusiasm. Pinned repos matter more than total repo count.
| Project Type | What It Demonstrates | Build Time | Recruiter Signal |
|---|---|---|---|
| Kaggle competition (top 25%) | Feature engineering, evaluation discipline | 3-5 weeks | Reproducibility |
| End-to-end ML system | Production thinking, deployment | 4-6 weeks | Can ship, not just train |
| Fine-tuned LLM + eval suite | LoRA/QLoRA, eval design, GenAI fluency | 3-4 weeks | Current ecosystem |
| Open-source PR (accepted) | Code review tolerance | 2-8 weeks | Peer-validated quality |
| Paper reimplementation | Method comprehension | 6-10 weeks | Academic depth (mixed) |
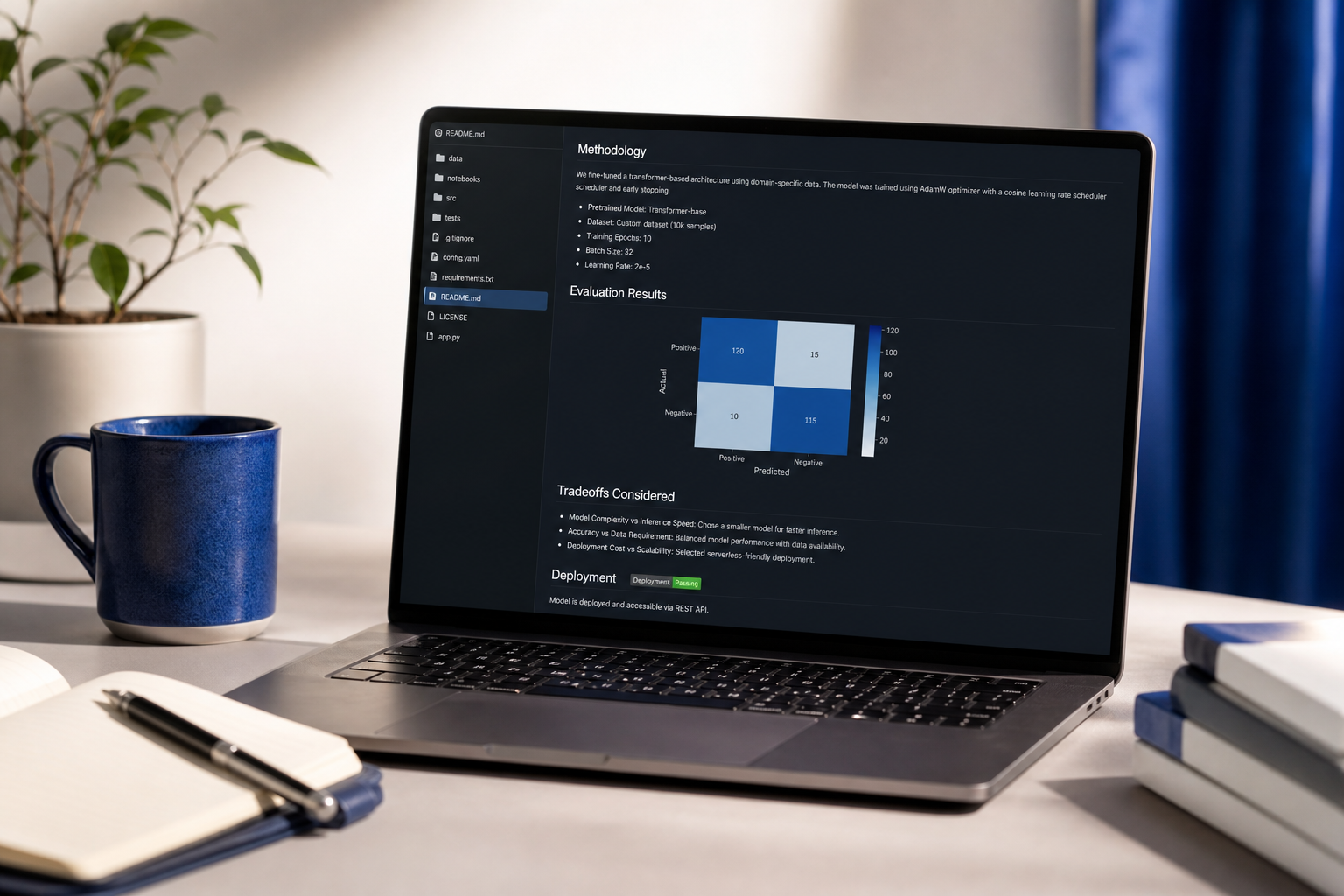
Breadth beats depth for entry-level candidates. Three medium-complexity projects across different domains — one tabular ML, one LLM, one deployment-focused — signals range. One brilliant research-paper reimplementation signals "academic, may not ship." Hiring managers at product-led companies read the second profile and pass. The exception: if you're targeting research labs (Anthropic, DeepMind, FAIR), invert this — depth wins.
The evaluation rubric is the project. Per the NIST AI RMF guidelines cited earlier, production AI systems require documented evaluation thresholds. A portfolio project without an evaluation report — precision/recall curves, fairness analysis across subgroups, error analysis on misclassified examples — reads as incomplete to senior engineers. The notebook is the easy part. The eval rigor is the differentiator.
Deployment matters more than model novelty. Recruiters increasingly prioritize candidates who can show a deployed system over those with higher Kaggle ranks but no shipped code. A modest model behind a working API beats a sophisticated notebook that never left Colab. The reason is unsexy but practical: in your first 90 days on the job, you'll ship a v1 system, not invent a new architecture. Hiring managers want evidence of the former.
Document the tradeoffs you rejected. A 500-word README explaining why you chose Random Forest over XGBoost, why you used cosine similarity over dot product in your RAG retrieval, what you'd do differently with more compute — this is the artifact that wins interviews. It demonstrates the judgment hiring managers can't test from a code review alone. Most candidates skip it because writing is harder than coding. Lean into the asymmetry.
The AI Engineering Toolkit: What's Actually Used in Production vs. Resume-Padding
This section is opinionated by design. The AI tooling landscape is noisy, and most LinkedIn "must-learn" lists are written by people selling courses on those exact tools. What follows is what production teams actually run in 2026.
Core ML frameworks — PyTorch wins for new learners. PyTorch dominates new research and most LLM tooling (Hugging Face, vLLM, Axolotl) is PyTorch-first. TensorFlow remains dominant inside Google and in some enterprise production environments built before 2022. Learn PyTorch first. If a target job requires TensorFlow, you can pick it up in about three weeks once you understand the underlying tensor and autograd primitives.
LLM ecosystem — Hugging Face is the floor, LangChain is optional. Hugging Face Transformers, Datasets, and the Hub are non-negotiable in 2026. LangChain is widely used but widely criticized for over-abstraction — many production teams have shifted to direct API calls with custom orchestration after hitting LangChain's leaky abstractions in incident postmortems. Learn enough LangChain to read other people's code; don't anchor your whole stack to it. LlamaIndex is the better choice for RAG-heavy applications. DSPy is worth watching but not yet a hiring requirement.
Resume-padding tools get you past the keyword filter and crushed in the technical interview. Pick the stack you can defend under questioning.
Evaluation tooling — the differentiator most candidates skip. This is the gap that separates senior from junior AI engineers in interviews, and the most under-invested skill area in self-taught roadmaps. Tools to learn: Promptfoo or Ragas for LLM evaluation, Evidently AI for tabular drift detection, Weights & Biases for experiment tracking. Per workflow analysis from independent industry analyst McKay Johns, production AI systems require evaluation protocols testing a minimum of 500 diverse inputs with documented error tolerances. If you can speak fluently about your evaluation methodology, you've already separated yourself from most applicants.
Deployment stack — start small, K8s is not your first hire's problem. Docker is essential. FastAPI for serving. Modal, Replicate, or Hugging Face Inference Endpoints for model hosting without infrastructure pain. Kubernetes is genuinely required at scale, but most AI engineering teams treat K8s as platform-team territory. Listing K8s on a junior resume without a real project that used it reads as padding. Better signal: a Dockerfile that produces an under-2GB image with proper layer caching.
Data and orchestration — pragmatic choices win. Pandas for sub-100GB datasets. DuckDB for analytical queries on Parquet files (criminally underused — it's the most efficient hour you can invest). Polars when Pandas becomes slow. Apache Spark only if your target employer explicitly runs it. For orchestration, Airflow is incumbent; Prefect and Dagster are gaining; pick based on job-posting frequency in your target market. For vector databases: pgvector if you already run Postgres, Pinecone if you need a managed service today, Weaviate if you need open-source with hybrid search.
When evaluating any new tool, ask three questions: Is it used by at least three companies you'd accept an offer from? Does it solve a problem you've actually hit, or are you preemptively learning it? Will it still be maintained in 18 months? Most "must-learn AI tools" on LinkedIn fail at least two of these checks. The fast-changing ecosystem rewards depth in a few stable layers, not breadth across the hype cycle. That's how we evaluate AI tool durability in adjacent domains too — same principle, same filter.
Convert Skills Into Offers: The Networking and Interview Playbook
Most "how to be an ai engineer" guides stop at "build skills." That's the easy half. The harder half — and the one that decides whether you're working in AI by month 14 or month 30 — is networking and interview narrative. Hiring is a distribution problem, not a meritocracy. Treat it that way.

1. Build in public, not in stealth. Post one technical write-up per month on a personal site, dev.to, or Substack. Share on LinkedIn three times a week about what you're building — not generic AI takes, but specific lessons from your projects. Per the IEEE Spectrum analysis cited earlier, the AI engineer talent market is noisy; visibility is a filter recruiters use before they even open your resume. If you don't have a site yet, design a personal site using an AI workflow and skip the two-week WordPress detour.
2. Cold-outreach 5 AI engineers per week at target companies. Not recruiters — engineers. Ask one specific question about their tech stack or a recent blog post they wrote. Conversion rate to a coffee chat is typically about 10-15% when the message is genuinely specific. Over 12 weeks, this yields roughly 6-9 informational interviews — historically the highest-converting top-of-funnel for engineering offers. Generic outreach converts at under 2%. The difference is reading their work before you message.
3. Frame portfolio projects as problems solved, not tools used. "Built a fraud detection model" loses to "Reduced false-positive rate from 12% to 4% on a 200K-transaction dataset by switching from logistic regression to gradient boosting and adding three engineered features." Numbers and decisions, not technology stacks. Recruiters skim for outcomes; engineers skim for reasoning. Both want quantified results.
4. Prepare for three distinct interview tracks. Coding (LeetCode medium, mostly arrays and hashmaps for AI roles — you don't need hard dynamic programming), ML system design (how would you build YouTube recommendations? how would you detect drift in production?), and applied ML (debug this notebook, explain this paper, critique this evaluation methodology). Allocate practice time across all three. Most candidates over-prepare on LeetCode and under-prepare on system design — exactly inverted from where the offers are won.
5. Negotiate entry routes, not just offers. Contract-to-FTE conversion at AI-native startups is increasingly common. Accepting a three-month paid contract with a stated FTE conversion path can bypass the standard hiring funnel entirely. Junior roles at consultancies (Slalom, Thoughtworks, BCG GAMMA) give 18-month exposure to varied AI projects at lower starting comp — weigh learning velocity versus comp explicitly. The role that maximizes your skill trajectory at month 24 is often not the highest first-year offer.
6. Participate in two communities, not seven. Pick one Slack or Discord (MLOps Community, Latent Space, Hugging Face Discord) and one in-person community (local AI meetup, one conference per year). Depth of presence in two communities beats lurking in seven. People recommend candidates they recognize. Recognition requires consistent, contributory presence — answering questions, sharing project updates, attending office hours.
7. Track your job search like a pipeline. Outreach sent, responses received, calls scheduled, take-homes received, on-sites, offers. Review weekly. If response rate is below 8%, your resume or outreach message needs revision before more volume helps. If take-home-to-on-site conversion is low, your code documentation is the bottleneck. If on-site-to-offer is low, your interview prep needs work. Debug the funnel where it leaks — same evaluation discipline you applied to your models.
Even strong candidates with shipped portfolios typically need 3-5 months of active search to land their first AI engineering role in 2026's market. The bar is high because the ceiling is high. The candidates who land offers are the ones who treat the search itself as a system to debug — not a lottery to enter. For more frameworks on building durable career and product systems, aymartech publishes adjacent playbooks worth bookmarking.
Common Questions About Becoming an AI Engineer in 2026
Do I need a CS degree to become an AI engineer?
No — but you need to compensate for what the degree signals. A CS degree gives recruiters a quick competence proxy: data structures, systems thinking, algorithmic intuition. Without it, your portfolio carries the full signaling load. Self-taught engineers who land roles typically have one strong open-source contribution showing code review tolerance, a deployed end-to-end project with a working URL, and demonstrable systems knowledge (Docker, basic networking, SQL). Per the CMU SEI analysis, the gap is rarely credentials — it's evaluation rigor and production discipline. The non-CS path adds roughly 4-6 months of timeline versus a CS graduate making the same transition. It's not closed. It's longer, and the bar for portfolio quality is higher.
What's the actual difference between a data scientist and an AI engineer?
Data scientists answer business questions with statistical models — heavy on experimentation, presentations, and stakeholder communication. AI engineers ship systems — heavy on production code, deployment, and monitoring. Data scientists typically work in Jupyter notebooks; AI engineers work in IDEs with version-controlled production code. Compensation diverges accordingly: training-industry data puts AI engineer salary bands at $130K-$250K+ versus $96K-$150K for data scientists in the US. The roles increasingly overlap at small startups but separate sharply at companies past 200 employees. If you enjoy shipping code more than presenting findings, target AI engineer.
Should I pursue a Master's degree or self-study?
Self-study works for most paths into AI engineering and saves about $40K-$120K in tuition. A Master's is worth it in three specific cases: you need a US work visa and the degree is your immigration pathway; you're targeting research roles at industrial labs (DeepMind, Anthropic, FAIR) where credentials still carry weight; or you're transitioning from a field with no quantitative track record on paper. Otherwise, the 18-24 month opportunity cost of a Master's typically outweighs the credential signal — especially compared to a strong portfolio built in the same timeframe with no tuition burden. The exception worth considering: part-time online programs like Georgia Tech OMSCS, which cost under $10K and don't pull you out of the job market.
How does regulation (EU AI Act, NIST AI RMF) affect entry-level AI engineer hiring?
It expands hiring, not contracts it. Regulatory requirements are creating demand for engineers who can build audit trails, document training data provenance, and implement bias testing thresholds. Candidates who can speak fluently to compliance requirements — even at a junior level — differentiate strongly in regulated industries like finance, healthcare, and public sector. Reading the NIST AI RMF once before interviews puts you ahead of the majority of entry-level candidates who treat compliance as someone else's problem. In practice, the candidates who pair modeling skill with regulatory literacy command a premium in healthcare and fintech specifically — those teams can't ship without that combination, and supply is thin.