
Cómo convertirse en ingeniero de IA en 2026: habilidades, hoja de ruta y herramientas
Tres Roles de Ingeniero de IA que Pagan Seis Cifras — Y Cuál se Ajusta a tu Trasfondo

Estás leyendo esto porque ya has hecho las cuentas sobre los salarios de ingeniero de IA — $130K a $250K+ en EE.UU. según datos de compensación de la industria de capacitación de Dataquest — y quieres saber qué se necesita realmente para llegar allí. La Oficina de Estadísticas Laborales de EE.UU. proyecta un crecimiento del 35% para científicos informáticos e investigadores (la categoría que incluye roles de IA) de 2022 a 2032, muy por encima del 4% promedio para todas las ocupaciones, según la BLS. La oportunidad es real. También lo es la pregunta de cómo ser ingeniero de IA cuando la mitad de internet te está vendiendo un bootcamp.
Aquí es donde se pone incómodo. Un análisis de IEEE Spectrum de listados de empleos de 2025 encontró que el 68% de publicaciones etiquetadas como "Ingeniero de IA" en realidad describen ingeniería de software avanzada con trabajo mínimo específico de IA, según IEEE Spectrum. Traducción: más de la mitad de los listados a los que estás solicitando no quieren lo que dice el título. La inflación de títulos es el secreto menos guardado del mercado.
Este artículo no pretende que serás contratado en 90 días. Te da la secuencia real — qué especialización elegir, qué fundamentos importan (y cuáles saltar), cómo construir un portafolio que sobreviva el clic de un ingeniero senior en GitHub, y cómo convertir habilidades en ofertas. Sin enlaces de afiliados de bootcamp. Sin hype.
Tabla de Contenidos
- Tres Roles de Ingeniero de IA que Pagan Seis Cifras — Y Cuál se Ajusta a tu Trasfondo
- Habilidades Fundamentales que Realmente te Contratan (Y la Teoría que Puedes Saltar)
- La Hoja de Ruta del Ingeniero de IA de 12 Meses: Una Secuencia Trimestral
- Proyectos de Portafolio que Realmente Obtienen Devoluciones de Reclutadores
- El Kit de Herramientas de Ingeniería de IA: Lo que se Usa Realmente en Producción vs. Relleno de Currículum
- Convierte Habilidades en Ofertas: El Cuaderno de Networking y Entrevistas
- Preguntas Comunes sobre Convertirse en Ingeniero de IA en 2026
Tres Roles de Ingeniero de IA que Pagan Seis Cifras — Y Cuál se Ajusta a tu Trasfondo
"Ingeniero de IA" es ahora un término paraguas. Los gerentes de contratación en Anthropic, Stripe y Mayo Clinic están buscando tres perfiles distintos, y las habilidades requeridas divergen bruscamente después del mes tres de aprendizaje. Elige uno antes de elegir un libro de texto. Elegir tarde significa desaprender un stack de framework diferente en el mes siete — esa es la razón más común por la que los cambios de carrera se queman.
Ingeniero de ML. Entrena modelos, diseña experimentos, escala pipelines de entrenamiento. Matemática pesada: álgebra lineal, probabilidad, teoría de optimización. Este es el camino en empresas con activos de datos propios — recomendaciones de Netflix, clasificación de Spotify, fraude de Stripe. Pasarás más tiempo en ingeniería de características y rigor de evaluación que en construir sistemas orientados al usuario. Buen ajuste para antecedentes en CS, estadística, física o matemática aplicada.
Ingeniero de LLM/GenAI. Construye aplicaciones sobre modelos de fundación. Pesado en ingeniería de prompts, generación aumentada por recuperación (RAG), arneses de evaluación y ajuste fino eficiente en parámetros con LoRA o QLoRA. Común en startups nativas de IA y equipos empresariales que envían copilots internos. La especialización de crecimiento más rápido en la contratación de 2025. Buen ajuste para ingenieros de producto e ingenieros full-stack — ya sabes cómo enviar; estás aprendiendo la capa de modelado.
Ingeniero de Sistemas de IA / MLOps. Posee implementación, monitoreo e infraestructura confiable. Pesado en Docker, Kubernetes, servicio de modelos (Triton, BentoML) y herramientas de observabilidad (Weights & Biases, Arize). Común en industrias reguladas — finanzas, atención médica, sector público — donde la estabilidad en producción importa más que la modelización novedosa. Buen ajuste para ingenieros backend, DevOps e ingenieros de confiabilidad del sitio que agregan el ciclo de vida del modelo a su toolkit existente.
| Rol | Profundidad Matemática | Herramientas Primarias | Banda Salarial Típica (EE.UU.) | Mejor Trasfondo de Entrada |
|---|---|---|---|---|
| Ingeniero de ML | Profunda | PyTorch, scikit-learn, Spark | $128K–$220K+ | CS, estadística, física |
| Ingeniero de LLM/GenAI | Moderada | Hugging Face, LangChain, LoRA, DBs vectoriales | $130K–$250K+ | Ingeniería de software |
| Sistemas de IA / MLOps | Ligera (nivel de sistema) | Docker, K8s, Triton, MLflow, W&B | $135K–$230K+ | Backend, DevOps, SRE |
Bandas salariales de datos de compensación de la industria de capacitación de Dataquest — verifica contra Levels.fyi para rangos de ofertas específicos.
El mercado aún no recompensa a los generalistas. Recompensa a los especialistas que pueden enviar un sistema funcional en su carril dentro de noventa días de contratación.
Según el Informe de Índice de IA 2025 de Stanford HAI, el 56% de las empresas ahora tienen roles de ingeniería de IA dedicados, arriba del 32% en 2023. La especialización de LLM/GenAI es la que crece más rápido en la contratación empresarial, pero la pista de MLOps tiene la tasa de conversión de ofertas más alta porque la oferta es genuinamente limitada — ingenieros backend que han obtenido profundidad en MLOps son más escasos que los tinkerers de LLM recién entrenados.
Compara esto con el hallazgo de IEEE sobre inflación de roles. El filtro de mayor palanca que puedes aplicar a tu búsqueda de empleo no es el título — es alinear tu especialización con el trabajo real descrito en una publicación. Lee la sección de responsabilidades. Si un rol de "Ingeniero de IA Senior" lista "diseñar APIs RESTful, optimizar consultas de PostgreSQL e integrar con webhooks de Stripe," eso es un rol backend con palabras clave de IA. Sigue adelante.
Habilidades Fundamentales que Realmente te Contratan (Y la Teoría que Puedes Saltar)
La mayoría de hojas de ruta de ingeniero de IA comienzan cargando seis meses de cálculo multivariable y teoría de medidas. No necesitas eso para ser contratado. Necesitas una comprensión funcional de cinco dominios — lo suficiente para leer un artículo, depurar un modelo y explicar una compensación en una entrevista. El Dr. Michael Chen del Instituto de Ingeniería de Software de CMU analizó 500 repos de GitHub de ingenieros de IA autodidactas y encontró que solo el 12% implementó marcos de evaluación adecuados, según CMU SEI. La brecha que mata ofertas rara vez es "más matemática." Es disciplina en producción.

Álgebra lineal y cálculo — solo el subconjunto de trabajo. Necesitas: operaciones matriciales (multiplicación, inversa, transposición), valores propios y vectores propios a nivel intuitivo, gradientes y la regla de la cadena, distribuciones de probabilidad básicas. Puedes saltar: análisis real, teoría de medidas, pruebas formales. La serie gratuita de YouTube "Essence of Linear Algebra" de 3Blue1Brown cubre aproximadamente el 80% del conocimiento de trabajo en unas cuatro horas. Si puedes derivar la retropropagación en papel para una red de dos capas, tienes suficiente.
Python — el ecosistema de IA, no solo el lenguaje. Más allá de la sintaxis: transmisión de arrays de NumPy, Pandas groupby, merge y operaciones de series de tiempo, tensores de PyTorch y autograd, async/await para trabajo de API, y empaquetamiento moderno con Poetry o uv. Los gerentes de contratación prueban comprensiones de listas, decoradores y gerenciadores de contexto en pantallas técnicas — no acertijos algorítmicos que verías en una entrevista de FAANG. Fluye en Python idiomático antes de tocar un modelo.
Estadística y diseño de evaluación. Prueba de hipótesis, intervalos de confianza, diseño de prueba A/B con cálculo del tamaño de muestra y corrección de comparaciones múltiples, y métricas de evaluación de modelos que van más allá de la precisión: compensaciones de precisión/recall, curvas ROC/AUC, calibración, BLEU y ROUGE para texto, y evaluación específica de LLM (LLM-as-judge, conjuntos dorados, recall@k de recuperación). Según el Marco de Gestión de Riesgos de IA del NIST, los sistemas en producción deben probar en mínimo un conjunto de evaluación curado con umbrales de sesgo y desempeño documentados. Si tu proyecto de portafolio carece de un informe de evaluación, se lee como incompleto.
SQL y manipulación de datos — innegociable, incluso para ingenieros de LLM. Cada sistema de IA en producción extrae de una base de datos. Necesitas: uniones (inner, left, funciones de ventana), CTEs, optimización de consultas (índices, planes EXPLAIN), y al menos una base de datos vectorial — pgvector, Pinecone o Weaviate — para trabajo de RAG. Salta Hadoop completamente. Aprende Spark solo si tus publicaciones de empleos objetivo la mencionan explícitamente. DuckDB es la gema subestimada que vale dos fines de semana de estudio.
Git, Docker y una plataforma en la nube. Estrategias de ramificación (trunk-based o GitHub Flow), escribir Dockerfiles que no produzcan bloat de imágenes de 8GB, e implementar en AWS, GCP o Azure. No necesitas Kubernetes para tu primer rol. La mayoría de equipos de ingeniería de IA tratan K8s como territorio del equipo de plataforma, no responsabilidad del ingeniero de modelado. Listar K8s en tu currículum sin un proyecto real que lo use se lee como relleno de currículum para entrevistadores experimentados.
El objetivo no es una cantidad de teoría de un título de CS. Es suficiente fluidez para enviar. Si puedes entrenar un modelo, evaluarlo en un conjunto retenido, implementarlo detrás de un endpoint de FastAPI y defender tu metodología de evaluación en una entrevista — has alcanzado la barra para la gran mayoría de roles de ingeniero de IA de nivel inicial.
La Hoja de Ruta del Ingeniero de IA de 12 Meses: Una Secuencia Trimestral
Los proveedores de capacitación como Dataquest sugieren que un ingeniero de software puede hacer la transición en 3-5 meses — etiqueta eso como estimación de vendedor, no consenso de la industria. El análisis de CMU SEI sugiere que ese cronograma es poco realista para trabajo de calidad en producción para alguien que comienza desde cero. El cronograma realista: aproximadamente 12 meses a tiempo parcial (15-20 horas por semana) para un trasfondo sin CS para alcanzar competencia contratable, aproximadamente 6-8 meses para un ingeniero de software trabajando que añade especialización en IA. Esta hoja de ruta asume el camino más largo. Comprime bajo tu propio riesgo.

Trimestre 1 (Meses 1–3): Python Básico + Repaso Matemático + Primer Cuaderno Enviado
Enfoque diario: 60% práctica de Python, Pandas y NumPy, 30% álgebra lineal vía 3Blue1Brown y Khan Academy, 10% lectura de publicaciones de empleo de ingeniería de IA para internalizar lo que "listo" se ve en tu mercado objetivo. Leer publicaciones no es procrastinación — es investigación de mercado.
Recursos gratuitos recomendados: Curso de Aprendizaje Profundo Práctico 1 de fast.ai, pista "Intro to Machine Learning" de Kaggle y el Curso de PNL de Hugging Face. Los tres son genuinamente gratuitos y construidos por profesionales que envían.
Hito de portafolio: Una entrada en competencia de Kaggle con un cuaderno público documentando tus decisiones de ingeniería de características y ratificación de elección de modelo. Criterios de salida: puedes cargar un CSV, entrenar un modelo de scikit-learn de línea de base, evaluarlo en un conjunto retenido y explicar en un párrafo por qué elegiste tu métrica de evaluación sobre las alternativas.
Trimestre 2 (Meses 4–6): Fundamentos de ML + Primer Proyecto End-to-End
Enfoque diario: profundización en scikit-learn, rigor de evaluación de modelos, introducción a PyTorch. Temas que importan: regularización, validación cruzada, ajuste de hiperparámetros, por qué tu conjunto de prueba se filtró (lo hará), y calibración. El modo de fallo más común para ingenieros autodidactas: desempeño del conjunto de entrenamiento que no sobrevive el contacto con datos de retención real.
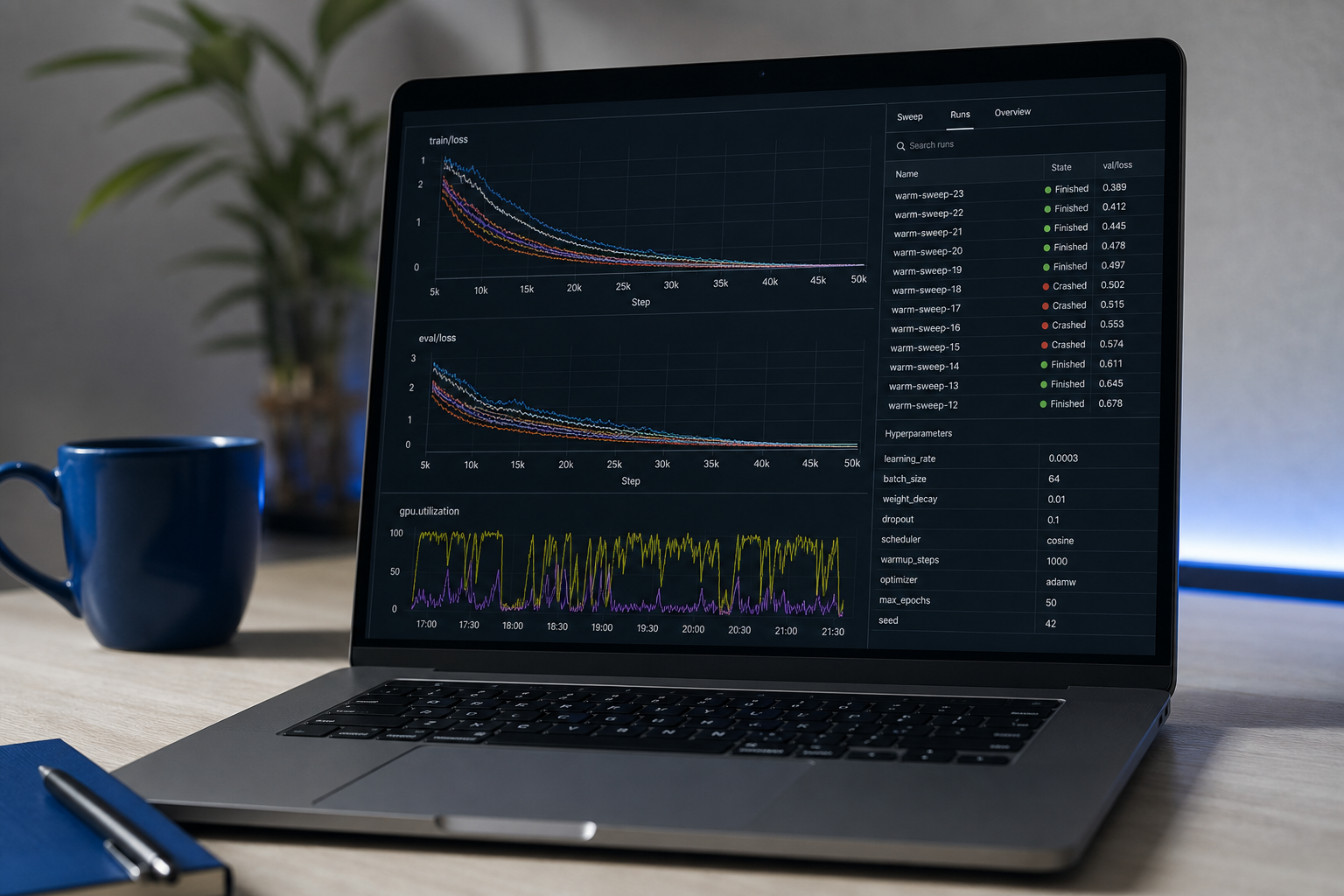
Hito de portafolio #1: Un proyecto end-to-end con datos limpios, un modelo entrenado, un informe de evaluación y un endpoint de inferencia de FastAPI implementado en Railway, Fly.io o Hugging Face Spaces. Criterios de salida: una URL de demostración funcional que alguien puede acceder, con un README explicando metodología y limitaciones conocidas. La URL implementada no es negociable — un cuaderno que vive en Colab señala trabajo incompleto.
Trimestre 3 (Meses 7–9): Aprendizaje Profundo + Elección de Especialización
Aquí es donde te comprometes con una de las tres especializaciones anteriores. Deja de cubrirte.
Ruta de Ingeniero de ML: Fundamentos de PyTorch, bucles de entrenamiento que escribiste tú mismo (no Lightning), conceptos básicos de entrenamiento distribuido (DDP), un intento de medalla de Kaggle con experimentación documentada.
Ruta de Ingeniero de LLM: Transformers de Hugging Face, ajuste fino de LoRA y QLoRA en un conjunto de datos de dominio, un pipeline de RAG completo con una base de datos vectorial, y un arnés de evaluación de LLM usando Promptfoo o Ragas.
Ruta de MLOps: Docker para flujos de trabajo de ML, registros de modelos vía MLflow, monitoreo de desviación con Evidently o Arize y pipelines de CI/CD que reentrena modelos en un cronograma.
Hito de portafolio #2: Un proyecto específico de especialización. Para LLM: un modelo de dominio ajustado fino con un conjunto de evaluación documentado cubriendo al menos 200 prompts. Para MLOps: un modelo implementado con tableros de monitoreo y un disparador de reentrenamiento automatizado.
Aprender un framework profundamente hace el segundo obvio. Aprender dos frameworks superficialmente te hace útil para ninguno.
Trimestre 4 (Meses 10–12): Código Abierto, Networking, Preparación de Entrevistas
Enfoque diario: una contribución de código abierto (Hugging Face, LangChain, scikit-learn — comienza con PRs de documentación para aprender el flujo de contribución), dos mensajes de outreach frío por día, y una sesión de preparación de entrevista combinando un medio de LeetCode con práctica de diseño de sistemas de ML.
Hito de portafolio: un PR aceptado a un repositorio reconocido, más un write-up técnico de menos de 1.500 palabras en tu sitio personal o Substack sobre una compensación que encontraste en tus proyectos de portafolio. Estos write-ups técnicos que construyen visibilidad de búsqueda son el artefacto que convierte outreach de reclutador frío en respuestas cálidas.
Criterios de salida: tres o más conversaciones activas de reclutador, una referencia de contrato pagado o mantenedor de código abierto, y un currículum pulido alineado con tu especialización elegida.
Una nota sobre adaptabilidad como meta-habilidad: el ecosistema de LLM cambió tres veces en 2024 — RAG, luego agentes, luego uso de herramientas. La hoja de ruta anterior te enseña la capa duradera (matemática, evaluación, implementación) para que puedas absorber el próximo cambio sin reiniciar desde cero. Los candidatos que prosperan a largo plazo no son los que memorizaron el stack de este año. Son los que construyeron el juicio para evaluar el del próximo año.
Proyectos de Portafolio que Realmente Obtienen Devoluciones de Reclutadores
Un portafolio es un filtro de contratación, no una salida creativa. Los reclutadores pasan un promedio de seis segundos en un currículum y aproximadamente 90 segundos haciendo clic a través de GitHub. Tu trabajo: hacer que los primeros tres proyectos que vean señalicen preparación en producción, no entusiasmo de aficionado. Los repos fijados importan más que el conteo total de repos.
| Tipo de Proyecto | Lo que Demuestra | Tiempo de Construcción | Señal de Reclutador |
|---|---|---|---|
| Competencia de Kaggle (top 25%) | Ingeniería de características, disciplina de evaluación | 3-5 semanas | Reproducibilidad |
| Sistema de ML end-to-end | Pensamiento de producción, implementación | 4-6 semanas | Puede enviar, no solo entrenar |
| LLM ajustado fino + conjunto de eval | LoRA/QLoRA, diseño de eval, fluidez de GenAI | 3-4 semanas | Ecosistema actual |
| PR de código abierto (aceptado) | Tolerancia a revisión de código | 2-8 semanas | Calidad validada por pares |
| Reimplementación de artículo | Comprensión de método | 6-10 semanas | Profundidad académica (mixta) |
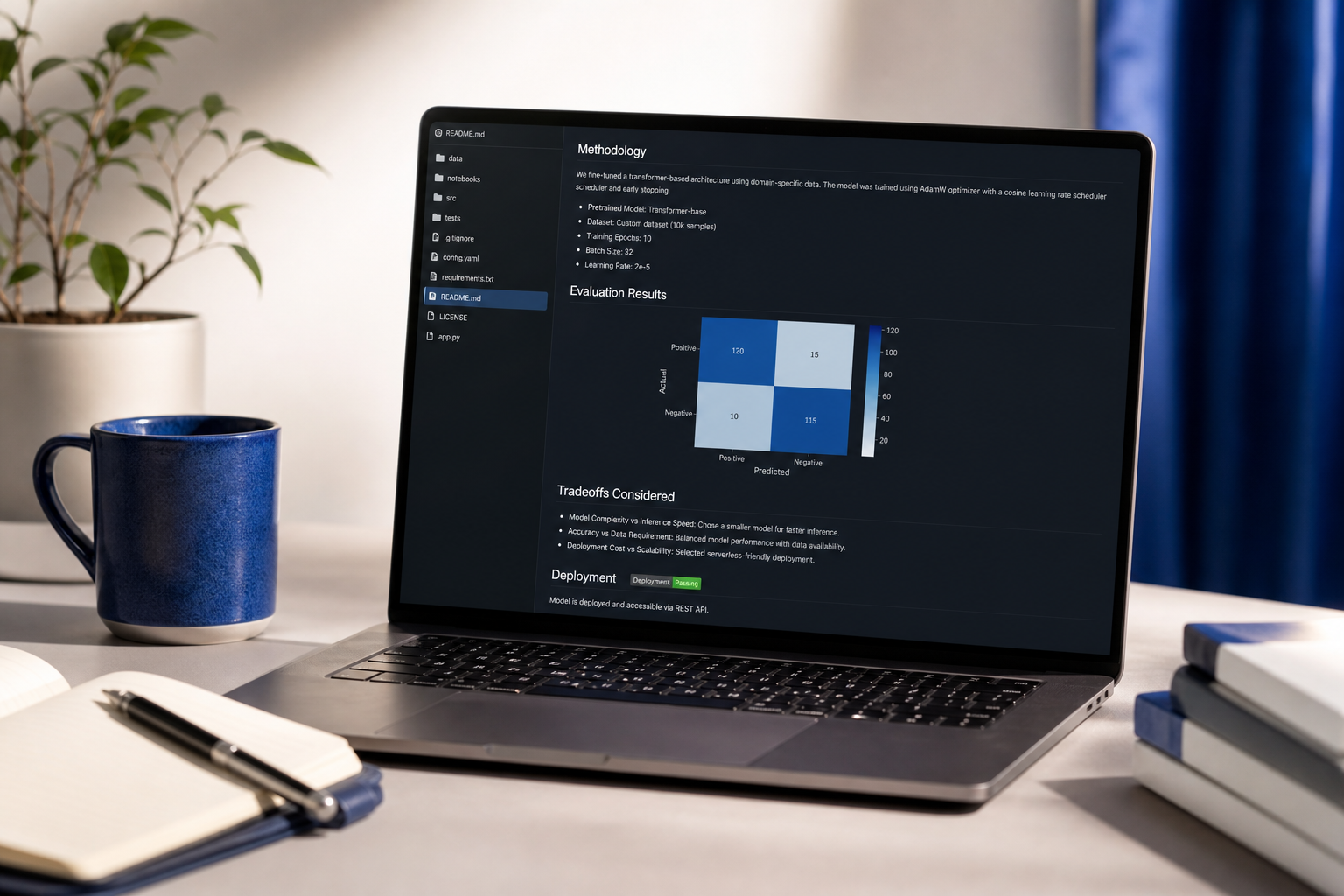
El amplitud gana profundidad para candidatos de nivel inicial. Tres proyectos de complejidad media en dominios diferentes — uno ML tabular, uno LLM, uno enfocado en implementación — señala rango. Una reimplementación brillante de artículo de investigación señala "académico, puede que no envíe." Los gerentes de contratación en empresas lideradas por producto leen el segundo perfil y avanzan. La excepción: si apuntas a laboratorios de investigación (Anthropic, DeepMind, FAIR), invierte esto — la profundidad gana.
El rúbrica de evaluación es el proyecto. Según las pautas del NIST AI RMF citadas anteriormente, los sistemas de IA en producción requieren umbrales de evaluación documentados. Un proyecto de portafolio sin un informe de evaluación — curvas de precisión/recall, análisis de equidad entre subgrupos, análisis de error en ejemplos mal clasificados — se lee como incompleto para ingenieros senior. El cuaderno es la parte fácil. El rigor de eval es el diferenciador.
La implementación importa más que la novedad del modelo. Los reclutadores priorizan cada vez más a candidatos que pueden mostrar un sistema implementado sobre aquellos con rangos de Kaggle más altos pero sin código enviado. Un modelo modesto detrás de una API funcional gana a un cuaderno sofisticado que nunca salió de Colab. La razón es poco glamorosa pero práctica: en tus primeros 90 días en el trabajo, enviarás un sistema v1, no inventarás una nueva arquitectura. Los gerentes de contratación quieren evidencia de lo primero.
Documenta las compensaciones que rechazaste. Un README de 500 palabras explicando por qué elegiste Random Forest sobre XGBoost, por qué usaste similitud de coseno sobre producto punto en tu recuperación de RAG, qué harías diferente con más compute — este es el artefacto que gana entrevistas. Demuestra el juicio que los gerentes de contratación no pueden probar desde una revisión de código solo. La mayoría de candidatos lo saltan porque escribir es más duro que codificar. Aprovecha la asimetría.
El Kit de Herramientas de Ingeniería de IA: Lo que se Usa Realmente en Producción vs. Relleno de Currículum
Esta sección es opinada por diseño. El panorama de herramientas de IA es ruidoso, y la mayoría de listas "imprescindibles" de LinkedIn son escritas por personas vendiendo cursos sobre esas herramientas exactas. Lo que sigue es lo que los equipos de producción realmente ejecutan en 2026.
Frameworks de ML básicos — PyTorch gana para nuevos aprendices. PyTorch domina la nueva investigación y la mayoría de herramientas de LLM (Hugging Face, vLLM, Axolotl) son primero PyTorch. TensorFlow sigue siendo dominante dentro de Google y en algunos entornos de producción empresarial construidos antes de 2022. Aprende PyTorch primero. Si un trabajo objetivo requiere TensorFlow, puedes aprenderlo en aproximadamente tres semanas una vez que entiendes los primitivos tensores y autograd subyacentes.
Ecosistema de LLM — Hugging Face es el piso, LangChain es opcional. Transformers de Hugging Face, Datasets y el Hub son innegociables en 2026. LangChain es ampliamente usado pero ampliamente criticado por sobre-abstracción — muchos equipos de producción han cambiado a llamadas de API directas con orquestación personalizada después de golpear las abstracciones perdedoras de LangChain en postmortems de incidentes. Aprende suficiente LangChain para leer código de otras personas; no ancles todo tu stack a ella. LlamaIndex es la mejor opción para aplicaciones pesadas en RAG. DSPy vale la pena ver pero aún no es un requisito de contratación.
Las herramientas de relleno de currículum te pasan el filtro de palabras clave y te aplastan en la entrevista técnica. Elige el stack que puedas defender bajo interrogatorio.
Herramientas de evaluación — el diferenciador que la mayoría de candidatos salta. Esta es la brecha que separa a ingenieros senior de junior en entrevistas, y el área de habilidad más inversa en hojas de ruta autodidactas. Herramientas para aprender: Promptfoo o Ragas para evaluación de LLM, Evidently AI para detección de desviación tabular, Weights & Biases para seguimiento de experimentos. Según análisis de flujo de trabajo de analista independiente McKay Johns, los sistemas de IA en producción requieren protocolos de evaluación probando mínimo 500 entradas diversas con tolerancias de error documentadas. Si puedes hablar fluidamente sobre tu metodología de evaluación, ya te has separado de la mayoría de candidatos.
Stack de implementación — comienza pequeño, K8s no es el primer problema de tu contratación. Docker es esencial. FastAPI para servicio. Modal, Replicate o Hugging Face Inference Endpoints para hosting de modelos sin dolor de infraestructura. Kubernetes es genuinamente requerido a escala, pero la mayoría de equipos de ingeniería de IA tratan K8s como territorio de equipo de plataforma. Listar K8s en un currículum junior sin un proyecto real que lo usó se lee como relleno. Mejor señal: un Dockerfile que produce una imagen bajo 2GB con caching de capa adecuado.
Datos y orquestación — las opciones pragmáticas ganan. Pandas para conjuntos de datos sub-100GB. DuckDB para consultas analíticas en archivos Parquet (criminalmente subutilizado — es la hora más eficiente que puedes invertir). Polars cuando Pandas se vuelve lento. Apache Spark solo si tu empleador objetivo explícitamente lo ejecuta. Para orquestación, Airflow es incumbente; Prefect y Dagster están ganando; elige según la frecuencia de publicación de empleos en tu mercado objetivo. Para bases de datos vectoriales: pgvector si ya ejecutas Postgres, Pinecone si necesitas un servicio gestionado hoy, Weaviate si necesitas de código abierto con búsqueda híbrida.
Al evaluar cualquier herramienta nueva, haz tres preguntas: ¿Es usada por al menos tres empresas para las que aceptarías una oferta? ¿Resuelve un problema que realmente has golpeado, o la estás aprendiendo preventivamente? ¿Seguirá siendo mantenida en 18 meses? La mayoría de "herramientas de IA imprescindibles" en LinkedIn fallan al menos dos de estos controles. El ecosistema que cambia rápido recompensa profundidad en pocas capas estables, no amplitud a través del ciclo de hype. Así es como evaluamos durabilidad de herramienta de IA en dominios adyacentes también — mismo principio, mismo filtro.
Convierte Habilidades en Ofertas: El Cuaderno de Networking y Entrevistas
La mayoría de guías "cómo ser ingeniero de IA" se detienen en "construir habilidades." Esa es la mitad fácil. La mitad más dura — y la que decide si estás trabajando en IA en el mes 14 o mes 30 — es networking y narrativa de entrevista. La contratación es un problema de distribución, no una meritocracia. Trátalo así.

1. Construye en público, no en secreto. Publica un write-up técnico por mes en un sitio personal, dev.to o Substack. Comparte en LinkedIn tres veces a la semana sobre lo que estás construyendo — no tomas genéricas de IA, sino lecciones específicas de tus proyectos. Según el análisis de IEEE Spectrum citado anteriormente, el mercado de talento de ingeniero de IA es ruidoso; la visibilidad es un filtro que los reclutadores usan antes de que siquiera abran tu currículum. Si no tienes sitio aún, diseña un sitio personal usando un flujo de trabajo de IA y salta el desvío de WordPress de dos semanas.
2. Outreach frío 5 ingenieros de IA por semana en empresas objetivo. No reclutadores — ingenieros. Haz una pregunta específica sobre su stack de tecnología o un artículo reciente que escribieron. La tasa de conversión a un café de chat es típicamente alrededor del 10-15% cuando el mensaje es genuinamente específico. Sobre 12 semanas, esto rinde aproximadamente 6-9 entrevistas informacionales — históricamente el canal superior de embudo de conversión más alto para ofertas de ingeniería. El outreach genérico convierte a menos del 2%. La diferencia es leer su trabajo antes de que lo mensajees.
3. Enmarca proyectos de portafolio como problemas resueltos, no herramientas usadas. "Construí un modelo de detección de fraude" pierde ante "Reduje la tasa de falso positivo del 12% al 4% en un conjunto de datos de 200K transacciones cambiando de regresión logística a gradient boosting y agregando tres características ingenieriles." Números y decisiones, no stacks de tecnología. Los reclutadores escanean resultados; los ingenieros escanean razonamiento. Ambos quieren resultados cuantificados.
4. Prepárate para tres pistas de entrevista distintas. Codificación (LeetCode medio, principalmente arrays y hashmaps para roles de IA — no necesitas programación dinámica dura que verías en una entrevista de FAANG), diseño de sistemas de ML (¿cómo construirías recomendaciones de YouTube? ¿cómo detectarías desviación en producción?) e IA aplicada (depura este cuaderno, explica este artículo, critica esta metodología de evaluación). Asigna tiempo de práctica en las tres. La mayoría de candidatos sobrepreparación en LeetCode e infrapreparación en diseño de sistemas — exactamente invertido de donde ganan las ofertas.
5. Negocia rutas de entrada, no solo ofertas. La conversión de contrato a FTE en startups nativos de IA es cada vez más común. Aceptar un contrato pagado de tres meses con una ruta FTE declarada puede saltarse toda la tubería de contratación estándar. Roles junior en consultorías (Slalom, Thoughtworks, BCG GAMMA) dan exposición de 18 meses a proyectos variados de IA a comp de inicio más bajo — pesa la velocidad de aprendizaje contra comp explícitamente. El rol que maximiza tu trayectoria de habilidad en el mes 24 a menudo no es la oferta del primer año más alta.
6. Participa en dos comunidades, no siete. Elige uno Slack o Discord (Comunidad MLOps, Latent Space, Discord de Hugging Face) y una comunidad en persona (meetup local de IA, una conferencia por año). La profundidad de presencia en dos comunidades bate merodeo en siete. Las personas recomiendan candidatos que reconocen. El reconocimiento requiere presencia consistente y contributoria — responder preguntas, compartir actualizaciones de proyecto, asistir a horas de oficina.
7. Rastrea tu búsqueda de empleo como una tubería. Outreach enviado, respuestas recibidas, llamadas programadas, take-homes recibidos, on-sites, ofertas. Revisa semanalmente. Si la tasa de respuesta está bajo 8%, tu currículum o mensaje de outreach necesita revisión antes de que ayude más volumen. Si la conversión de take-home a on-site es baja, tu documentación de código es el cuello de botella. Si la conversión de on-site a oferta es baja, tu preparación de entrevista necesita trabajo. Depura la tubería donde se filtra — misma disciplina de evaluación que aplicaste a tus modelos.
Incluso candidatos fuertes con portafolios enviados típicamente necesitan 3-5 meses de búsqueda activa para aterrizar su primer rol de ingeniero de IA en el mercado de 2026. La barra es alta porque el techo es alto. Los candidatos que aterrizan ofertas son aquellos que tratan la búsqueda en sí como un sistema para depurar — no una lotería para ingresar. Para más marcos en construcción de sistemas de carrera y producto duraderos, aymartech publica cuadernos adyacentes que vale la pena marcar.
Preguntas Comunes sobre Convertirse en Ingeniero de IA en 2026
¿Necesito un título de CS para convertirme en ingeniero de IA?
No — pero necesitas compensar por lo que señala el título. Un título de CS da a los reclutadores un proxy rápido de competencia: estructuras de datos, pensamiento de sistemas, intuición algorítmica. Sin él, tu portafolio lleva la carga de señalización completa. Los ingenieros autodidactas que aterrizan roles típicamente tienen una contribución de código abierto fuerte mostrando tolerancia a revisión de código, un proyecto end-to-end implementado con una URL funcional, y conocimiento demostrativo de sistemas (Docker, redes básicas, SQL). Según el análisis de CMU SEI, la brecha rara vez son credenciales — es rigor de evaluación y disciplina en producción. El camino sin CS agrega aproximadamente 4-6 meses de cronograma versus un graduado de CS haciendo la misma transición. No se cierra. Es más largo, y la barra para calidad de portafolio es más alta.
¿Cuál es la diferencia real entre un científico de datos e ingeniero de IA?
Los científicos de datos responden preguntas comerciales con modelos estadísticos — pesados en experimentación, presentaciones y comunicación con stakeholders. Los ingenieros de IA envían sistemas — pesados en código de producción, implementación y monitoreo. Los científicos de datos típicamente trabajan en cuadernos de Jupyter; los ingenieros de IA trabajan en IDEs con código de producción versionado. La compensación diverge en consecuencia: datos de la industria de capacitación ponen bandas salariales de ingeniero de IA en $130K-$250K+ versus $96K-$150K para científicos de datos en EE.UU. Los roles cada vez se solapan más en startups pequeños pero se separan bruscamente en empresas pasadas 200 empleados. Si disfrutas enviando código más que presentar hallazgos, apunta a ingeniero de IA.
¿Debo cursar una Maestría o auto-estudio?
El auto-estudio funciona para la mayoría de caminos en ingeniería de IA y guarda aproximadamente $40K-$120K en matrícula. Una Maestría vale la pena en tres casos específicos: necesitas una visa de trabajo de EE.UU. y el título es tu camino de inmigración; estás apuntando a roles de investigación en laboratorios industriales (DeepMind, Anthropic, FAIR) donde las credenciales aún llevan peso; o estás haciendo transición desde un campo sin historial cuantitativo en papel. Por lo demás, el costo de oportunidad de 18-24 meses de una Maestría típicamente supera la señal de credencial — especialmente en comparación con un portafolio fuerte construido en el mismo tiempo sin carga de matrícula. La excepción que vale considerar: programas en línea a tiempo parcial como Georgia Tech OMSCS, que cuesta bajo $10K y no te saca del mercado laboral.
¿Cómo afecta la regulación (Ley de IA de la UE, Marco de RMF de IA del NIST) la contratación de ingenieros de nivel inicial?
Expande la contratación, no la contrae. Los requisitos reguladores están creando demanda de ingenieros que pueden construir rastros de auditoría, documentar la procedencia de datos de entrenamiento e implementar umbrales de prueba de sesgo. Los candidatos que pueden hablar fluidamente sobre requisitos de cumplimiento — incluso a nivel junior — se diferencian fuertemente en industrias reguladas como finanzas, atención médica y sector público. Leer el Marco de RMF de IA del NIST una vez antes de entrevistas te pone por delante de la mayoría de candidatos de nivel inicial que tratan el cumplimiento como responsabilidad de alguien más. En la práctica, los candidatos que combinan habilidad de modelado con alfabetización regulatoria comandan una prima en servicios de salud y fintech específicamente — esos equipos no pueden enviar sin esa combinación, y la oferta es delgada.